在互联网时代,网站内容被搜索引擎收录是常见的现象,但有时出于隐私保护、内容版权、内容未成熟或特定运营策略等考虑,网站所有者可能不希望某些页面或整个网站被百度收录,要实现这一目标,需要综合运用技术手段、平台规则设置和内容管理策略,以下从多个维度详细说明如何不让百度收录相关内容。

使用robots.txt文件引导爬虫行为
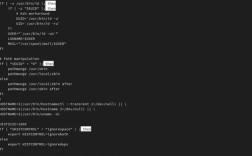
robots.txt是网站根目录下的文本文件,用于告知搜索引擎爬虫哪些页面可以抓取,哪些禁止抓取,这是最基础也是最直接的管控方式,其核心语法包括“User-agent”(指定爬虫名称,如Baiduspider代表百度爬虫)、“Allow”(允许抓取)、“Disallow”(禁止抓取),若想禁止百度爬虫抓取整个网站,可编写内容为:“User-agent: Baiduspider Disallow: /”;若仅禁止抓取特定目录(如/admin/和/private/),则可写:“User-agent: Baiduspider Disallow: /admin/ Disallow: //private/”,需注意,robots.txt仅是“建议性”协议,部分恶意爬虫可能忽略该文件,因此需配合其他手段使用,确保文件语法正确,避免因错误配置导致意外禁止收录。
通过meta标签控制单页面收录
对于单个HTML页面,可在代码的<head>部分添加特定的meta标签,直接指令搜索引擎禁止收录该页面,常用标签包括:<meta name="robots" content="noindex,nofollow">,noindex”表示禁止索引该页面(即不收录到搜索结果),“nofollow”表示禁止跟踪该页面内的链接,若仅禁止索引但允许跟踪链接,可使用<meta name="robots" content="noindex,follow>,该方法的优点是针对性强,无需服务器配置,适合动态页面或临时性禁止收录的场景,但需注意,meta标签仅对支持该协议的搜索引擎有效,且需确保每个目标页面均正确添加。
设置HTTP头信息禁止收录
对于动态网站或API接口,可通过服务器返回的HTTP头信息中的X-Robots-Tag指令控制爬虫行为,在PHP中可通过header('X-Robots-Tag: noindex, nofollow');设置,在Nginx配置中可添加add_header X-Robots-Tag "noindex, nofollow";,该方法的meta标签作用类似,但适用于非HTML内容(如PDF、图片、视频等),可实现更精细化的控制,禁止百度收录某PDF文件,可在服务器响应头中添加X-Robots-Tag: noindex,需确保服务器正确配置,且该头信息会被百度爬虫识别。
利用百度站长平台工具提交禁止收录申请
百度站长平台提供了“URL提交”和“robots.txt检测”功能,同时支持通过“死链提交”功能间接禁止收录,具体操作为:将不希望收录的页面URL整理为死链文件(如deadlink.txt),通过站长平台的“死链提交”工具提交,百度会定期处理死链文件,将这些URL从索引中移除,若页面已收录,可在站长平台的“索引量”中找到对应URL,通过“快速去重”功能申请快速删除,需注意,去重申请需提供合理的理由,且处理时间通常为3-10个工作日。

内容加密或访问权限控制
对于高度敏感或私密内容,可通过技术手段限制爬虫抓取。
- 登录访问设置为用户登录后才可查看,百度爬虫无法模拟登录行为,因此无法抓取需登录的内容。
- IP访问限制:通过服务器配置(如iptables或Nginx的deny指令)限制特定IP段访问,百度爬虫的IP地址可通过公开渠道获取并加入黑名单。
- 加载:使用JavaScript动态渲染页面内容,百度爬虫对JS的解析能力有限,可能无法抓取完整内容,但需注意百度已逐步提升JS解析能力,此方法并非绝对可靠。
发布与更新策略
从源头减少可被收录的内容,也是有效的间接手段:
- 处理:对于测试页面、草稿或活动页面,使用“nofollow”标签或临时加密,待正式发布后再开放。 去重**:避免发布高度重复或转载内容,百度对重复内容的收录意愿较低,原创内容反而更容易被收录。
- 定期清理旧内容:对不再需要的内容及时删除,并返回404状态码或410状态码(410表示永久删除,比404更明确告知搜索引擎内容已不存在)。
常见禁止收录方法的适用场景对比
为了更直观地选择合适的方法,以下通过表格对比常见手段的适用场景:
| 方法 | 适用场景 | 优点 | 局限性 |
|---|---|---|---|
| robots.txt | 禁止抓取整个目录或特定文件 | 配置简单,支持批量设置 | 仅为建议协议,恶意爬虫可能忽略 |
| meta标签 | 单个HTML页面禁止索引 | 针对性强,无需服务器配置 | 仅支持HTML页面,需手动添加每个页面 |
| HTTP头信息(X-Robots-Tag) | 动态页面、API、非HTML内容 | 支持多格式内容,服务器级控制 | 需服务器配置权限 |
| 百度站长平台死链提交 | 已收录页面或批量URL去重 | 官方渠道处理,可靠 | 处理周期较长,需提交死链文件 |
| 登录/访问权限控制 | 高度私密内容(如用户个人中心) | 彻底阻止爬虫访问 | 可能影响用户体验 |
注意事项
- 避免误操作:错误配置robots.txt或meta标签可能导致整个网站无法被收录,建议在测试环境验证无误后再部署。
- 持续监控:使用百度站长平台的“索引量”工具和site指令(如site:example.com)定期检查收录情况,确保禁止措施生效。
- 法律合规:禁止收录的内容需符合法律法规,避免通过技术手段隐藏违法违规内容。
相关问答FAQs
Q1:robots.txt禁止抓取后,百度还会收录页面吗?
A:robots.txt仅告知爬虫“请勿抓取”,但百度仍可能基于其他途径(如外部链接)发现页面并尝试收录,若页面已被收录,需配合meta标签的noindex或站长平台去重功能彻底移除,robots.txt无法阻止页面在搜索结果中显示标题和链接(若已被收录),仅禁止抓取页面内容。

Q2:如何确保百度彻底删除已收录的页面?
A:删除已收录页面需分步骤操作:在服务器端删除页面文件并返回404或410状态码;通过百度站长平台提交“死链提交”或“快速去重”申请,提供页面URL;检查外部链接,若存在其他网站链向该页面,可联系对方站长移除链接,一般情况下,百度会在10-15天内完成删除,但热门或高权重页面可能需要更长时间。