,通常涉及通过技术手段和管理工具向搜索引擎传达“禁止抓取”的指令,核心方法包括设置robots.txt文件、使用meta标签、控制网站访问权限、提交sitemap以及联系搜索引擎官方支持等,以下是具体操作步骤和注意事项:

通过robots.txt文件禁止抓取
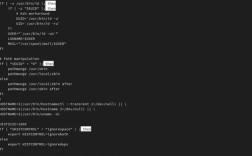
robots.txt是网站根目录下的纯文本文件,用于告知搜索引擎爬虫哪些页面可以抓取、哪些禁止抓取,是控制抓取范围最常用且有效的方式。
文件位置与格式
文件需放置在网站根目录(如https://example.com/robots.txt),语法分为“用户代理(User-agent)”“抓取路径(Disallow/Allow)”两部分。
- User-agent:指定生效的搜索引擎爬虫,如代表所有搜索引擎,
Googlebot代表谷歌爬虫,Baiduspider代表百度爬虫。 - Disallow:禁止抓取的路径,如
/admin/禁止抓取admin目录下所有页面;/private.html禁止抓取特定页面。 - Allow:在Disallow规则中允许例外路径,如
/admin/public/允许抓取admin下的public子目录。
常见规则示例
-
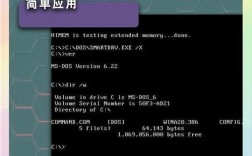
完全禁止抓取:
User-agent: * Disallow: /
表示所有搜索引擎禁止抓取网站全部内容。
 (图片来源网络,侵删)
(图片来源网络,侵删) -
禁止抓取特定目录:
User-agent: Baiduspider Disallow: /user/ Disallow: /temp/
仅禁止百度爬虫抓取user和temp目录,其他目录可正常抓取。
-
部分开放+部分禁止:
User-agent: * Allow: /public/ Disallow: /
仅允许抓取public目录下的内容(需注意“Allow”需在“Disallow”之前生效)。
 (图片来源网络,侵删)
(图片来源网络,侵删)
注意事项
- robots.txt仅作“建议”而非“强制”:恶意爬虫可能无视规则,需结合其他手段(如密码保护)提升安全性。
- 避免误写路径:错误规则可能导致重要页面被禁止抓取(如将
/allow/写成/alow/)。 - 及时检查语法:可通过谷歌“robots.txt测试工具”或百度搜索资源平台验证语法正确性。
使用meta标签禁止当前页面抓取
若仅需禁止单个页面被抓取(如隐私页、测试页),可在页面HTML的<head>部分添加meta标签。
标签语法
<meta name="robots" content="noindex, nofollow">
- noindex:禁止搜索引擎收录当前页面(页面不会被展示在搜索结果中)。
- nofollow:禁止搜索引擎抓取当前页面的外链(链接权重不会传递)。
适用场景
- 临时页面(如活动页、开发测试页)。
- 敏感信息页面(如用户隐私数据、后台管理页)。 页面(如打印页、移动端适配页,避免重复收录影响SEO)。
注意事项
- meta标签仅对当前页面生效,无法控制整站抓取。
- 若页面已被收录,需通过搜索引擎“URL移除工具”手动提交删除请求。
控制网站访问权限(技术限制)
对于完全不想被搜索引擎(或任何用户)访问的页面,可通过技术手段直接限制访问,使爬虫无法获取内容。
密码保护
- 服务器配置:通过Apache的
.htaccess或Nginx的htpasswd为目录设置访问密码,未授权用户(含爬虫)无法访问。- Apache示例(
.htaccess):AuthType Basic AuthName "Restricted Area" AuthUserFile /path/to/.htpasswd Require valid-user
- Apache示例(
- 建站工具插件:WordPress等平台可通过“限制访问”插件(如“Access Control”)设置密码保护。
IP限制
若网站仅允许特定IP访问(如内网系统),可在服务器层配置白名单,禁止搜索引擎爬虫的IP段访问。
- Nginx示例:
allow 192.168.1.100; deny all;
注意事项
- 技术限制会导致搜索引擎完全无法获取页面内容,适用于绝对私密页面,公开页面慎用。
提交sitemap与搜索引擎沟通
若需禁止搜索引擎抓取整站或大量页面,可通过官方平台提交sitemap并明确告知“禁止抓取”。
搜索引擎官方渠道
- 百度搜索资源平台:验证网站后,在“站点属性”中设置“抓取环境”(如“开发测试环境”),或在“URL提交”中提交robots.txt并标注“禁止抓取”。
- Google Search Console:在“robots.txt测试工具”中上传文件,若需完全禁止抓取,提交sitemap并选择“删除整个网站”。
- 其他搜索引擎:如必应、360等,均提供类似站长平台,提交robots.txt或通过“反馈表单”申请禁止抓取。
注意事项
- 完全禁止抓取后,网站将从搜索引擎结果中消失,需谨慎操作。
- 若需恢复抓取,需重新提交sitemap并更新robots.txt规则。
常见问题与解决方案(表格)
| 问题场景 | 可能原因 | 解决方案 |
|---|---|---|
| robots.txt已设置禁止,但页面仍被收录 | 爬虫无视规则、页面已被历史收录 | 检查robots.txt语法;通过搜索引擎“URL移除工具”提交删除请求 |
| meta标签添加“noindex”后,页面仍在搜索结果中 | 页面已被缓存、搜索引擎未及时更新 | 等待搜索引擎重新抓取(通常1-7天);手动提交“URL移除” |
| 整站禁止抓取后,仍发现外链指向被禁止页面 | 其他网站引用了禁止页面的URL | 联系对方网站管理员删除外链;通过“rel=canonical”规范权重 |
相关问答FAQs
Q1:robots.txt禁止抓取后,已收录的页面会自动删除吗?
A:不会,robots.txt仅禁止搜索引擎“抓取”新内容,已收录的页面需手动提交删除请求,在百度搜索资源平台选择“URL删除工具”,输入页面地址并等待审核(通常1-3天生效);Google Search Console则通过“旧版工具”中的“移除网址”提交。
Q2:如何禁止搜索引擎抓取移动端页面但允许抓取PC端页面?
A:通过robots.txt的“User-agent”区分移动端和PC端爬虫。
# 禁止所有移动端爬虫抓取 User-agent: Googlebot-Mobile User-agent: Baiduspider-mobile Disallow: / # 允许PC端爬虫抓取 User-agent: Googlebot User-agent: Baiduspider Disallow: /mobile/
确保移动端页面URL与PC端不同(如使用/m/前缀),并在PC端页面添加rel="canonical"指向PC版URL,避免权重分散。