要让百度不收录网站或特定页面,需要从技术手段、平台工具、内容策略等多维度综合实施,以下是具体操作方法和注意事项:

(图片来源网络,侵删)
技术层面阻止收录
设置Robots.txt协议
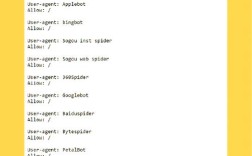
在网站根目录创建robots.txt文件,通过指令禁止百度蜘蛛爬取。
User-agent: Baiduspider
Disallow: / # 禁止爬取整个网站
或
Disallow: /admin/ # 仅禁止爬取后台目录
Allow: /public/ # 允许爬取公开目录需注意:百度蜘蛛可能不完全遵守该协议,敏感页面仍需配合其他方法。
使用meta robots标签
在HTML代码的<head>部分添加标签:
<meta name="robots" content="noindex,nofollow">
noindex:禁止收录页面内容nofollow:禁止传递该页面的权重
服务端返回HTTP头信息
通过服务器配置(如Apache的.htaccess或Nginx配置)返回禁止爬取的HTTP头:

(图片来源网络,侵删)
Header set X-Robots-Tag "noindex, nofollow"或直接返回403状态码(需谨慎,可能影响正常访问)。
密页或登录后访问内容
将需要保密的页面放在用户登录后才能访问的区域,百度蜘蛛因无法登录而无法爬取。
百度官方工具控制
使用百度站长平台
- 普通收录保护:在"普通收录"-"API提交"中,通过接口主动推送需要删除的页面,选择"删除URL"并选择"删除所有内容"或"仅删除快照"。
- 历史URL保护:对已收录的页面,提交"URL移出"申请,审核通过后百度会删除快照(通常1-3天生效)。
设置网站子链接保护
在百度站长平台的"网站改版"-"子链接保护"中,输入需要保护的URL前缀,百度会优先保留指定链接的权重。
内容策略与权限控制
与参数限制
对包含敏感信息的动态页面(如搜索结果页、用户数据页),通过robots.txt禁止爬取带特定参数的URL(如?id=123),或设置登录验证。

(图片来源网络,侵删)
定期清理过期内容
对已收录但不再需要的页面(如活动页、旧产品页),直接删除页面并在百度站长平台提交删除请求,避免页面被快照留存。
使用Canonical标签页面(如不同参数的同一商品页),通过<link rel="canonical" href="https://www.example.com/canonical-url">>指定权威链接,避免百度收录重复内容。
常见场景处理方案
| 场景 | 解决方案 |
|---|---|
| 整个网站不收录 | robots.txt设置Disallow: /,百度站长平台提交"删除整个网站" |
| 特定目录不收录 | robots.txt设置Disallow: /private/,目录内页面添加meta robots标签 |
| 已收录页面需删除 | 百度站长平台提交"URL移出",删除页面并返回404状态码 |
| 临时测试页面不收录 | 添加meta robots标签,测试完成后删除页面 |
| 用户隐私页面不收录 | 设置登录访问,robots.txt禁止爬取相关目录 |
注意事项
- 生效时间:技术设置(如robots.txt)生效较快,百度站长平台删除请求需1-7天审核,快照删除可能延迟更久。
- 替代方案:若仅想隐藏内容但保留页面,可使用
noindex标签而非删除页面,避免404影响网站结构。 - 违规风险:切勿通过虚假手段(如robots.txt允许但实际禁止爬取)欺骗百度,可能导致网站降权。
- 定期检查:通过
site:www.example.com命令监控收录情况,及时处理新收录的敏感页面。
相关问答FAQs
Q1:robots.txt禁止收录后,百度还会收录页面吗?
A:robots.txt是协议性指令,百度蜘蛛虽会遵守,但部分情况下仍可能收录页面(如其他网站链接指向),建议配合meta robots标签或百度站长平台提交删除请求,确保彻底禁止收录。
Q2:如何确保百度已删除页面快照?
A:在百度搜索框输入cache:页面URL,若无法显示快照则表示已删除,也可通过百度站长平台"索引量"工具查看页面是否仍在索引库中,持续提交删除直至快照消失。