要让百度不收录网站,需要从技术手段、配置设置和内容策略等多方面综合采取措施,百度作为国内主流搜索引擎,其爬虫会主动抓取互联网上的公开内容,若不想让网站被收录,核心思路是阻止爬虫抓取页面内容,并确保即使被抓取也不会被索引,以下是具体操作方法和注意事项:

技术手段阻止爬虫抓取
修改robots.txt文件
robots.txt是网站根目录下的文本文件,用于告知搜索引擎爬虫哪些页面可以抓取,哪些禁止抓取,通过合理配置robots.txt,可直接屏蔽百度爬虫(Baiduspider)。
配置示例:
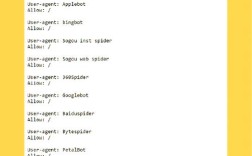
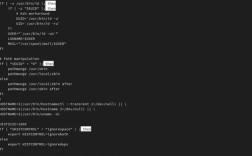
User-agent: Baiduspider Disallow: /
上述代码表示禁止Baiduspider抓取网站所有页面,若只想屏蔽部分目录(如后台管理页、用户隐私页),可具体指定路径:
User-agent: Baiduspider Disallow: /admin/ Disallow: /private/ Allow: /public/
注意事项:
- robots.txt仅能阻止“守规矩”的爬虫,恶意爬虫可能无视该文件,需配合其他手段。
- 确保文件路径正确(需放在网站根目录),且语法无错误(如Disallow后需加斜杠“/”)。
- 避免使用“Disallow: *”这类错误语法,可能导致所有页面被屏蔽。
使用meta标签禁止索引
在HTML页面的<head>部分添加meta标签,可针对单页面或特定目录禁止百度收录。
代码示例:

<meta name="robots" content="noindex, nofollow">
noindex:禁止百度索引该页面(即页面不会被收录到搜索结果中)。nofollow:禁止百度爬虫通过该页面的链接继续抓取其他页面。
若需全局禁止,可将该标签添加到网站的公共模板文件(如header.php),使其作用于所有页面。
设置HTTP头信息
通过服务器配置返回特定的HTTP头信息,可禁止百度爬虫抓取页面,在Nginx或Apache中配置X-Robots-Tag头:
Nginx配置示例:
location /private/ {
add_header X-Robots-Tag "noindex, nofollow";
}
Apache配置示例(.htaccess文件):
<FilesMatch "\.(php|html)$">
Header set X-Robots-Tag "noindex, nofollow"
</FilesMatch>
此方法适用于动态页面或特定目录,比meta标签更灵活,尤其适合无法修改HTML源码的场景。
服务器与域名级控制
使用密码保护目录
通过服务器工具(如Apache的.htaccess或Nginx的htpasswd)为目录设置访问密码,即使爬虫抓取到页面,也无法获取内容。
Apache配置示例:

AuthType Basic AuthName "Restricted Area" AuthUserFile /path/to/.htpasswd Require valid-user
访问时需输入用户名和密码,爬虫因无法认证而被拦截。
IP限制或User-Agent屏蔽
在服务器层面限制百度爬虫的IP或User-Agent,可阻止其访问网站。
Nginx配置示例(屏蔽Baiduspider):
if ($http_user_agent ~* "Baiduspider") {
return 403;
}
注意事项:
- 百度爬虫的User-Agent可能变化,需定期更新规则。
- 误屏蔽可能导致正常用户被拒绝(如用户浏览器UA与爬虫相似),需谨慎使用。
启用HTTPS并配置CSP
通过HTTPS加密传输内容,可防止中间人窃取数据;同时配置内容安全策略(CSP),限制页面资源的加载范围,间接降低爬虫抓取效率。
CSP配置示例:
<meta http-equiv="Content-Security-Policy" content="default-src 'self'">
此方法虽不能直接阻止爬虫,但可增强网站安全性,减少内容被恶意抓取的风险。
内容与策略调整
避免公开敏感页面
若网站包含不希望被收录的内容(如测试页、内部文档、用户生成内容等),可通过以下方式处理:
- 将页面移至非公开目录(如
/test/),并在robots.txt中禁止抓取。 - 使用登录才能访问的页面(如会员专区),爬虫因无法登录而被拦截。
- 动态生成内容(如通过JavaScript渲染),部分爬虫可能无法解析,但百度已支持部分JS渲染,需结合其他手段。
定期检查收录情况
即使采取上述措施,仍需定期检查百度是否收录了网站页面,可通过以下方式验证:
- 使用百度搜索指令
site:yourdomain.com查看收录结果。 - 登录百度站长工具(需验证网站),查看“索引量”数据。
若发现意外收录,需排查robots.txt配置或meta标签是否生效,并重新提交“删除网址”请求。
考虑网站类型与需求
- 临时性网站:若网站仅为短期使用(如活动页面),可在活动结束后直接关闭服务器,彻底避免被收录。
- 企业内部网站:可通过内网部署(如仅公司内网访问),或使用VPN限制访问,从根本上杜绝爬虫抓取。
不同场景下的策略对比
| 场景 | 推荐方法 | 优缺点 |
|---|---|---|
| 全站禁止收录 | robots.txt + 全站meta标签noindex |
优点:简单直接;缺点:需确保配置无误,且无法阻止恶意爬虫抓取。 |
| 部分目录禁止 | robots.txt指定路径 + HTTP头X-Robots-Tag |
优点:灵活可控;缺点:需维护多套规则,易遗漏路径。 |
| 动态页面或单页应用 | meta标签noindex + 服务器返回404/410状态码(针对已删除页面) |
优点:适合SPA;缺点:需确保状态码正确,避免误导爬虫。 |
相关问答FAQs
Q1: robots.txt禁止抓取后,百度是否还会收录页面?
A: robots.txt仅能阻止爬虫抓取页面内容,但若页面已被其他网站链接或手动提交至百度,仍可能被临时收录,若robots.txt配置错误(如语法错误),爬虫可能无视规则,建议配合meta标签noindex使用,确保即使被抓取也不会被索引。
Q2: 如何彻底删除百度已收录的页面?
A: 删除已收录页面需分两步:① 修改robots.txt允许抓取该页面,或在页面中添加meta name="robots" content="noindex";② 登录百度站长工具,在“索引提交”中选择“删除网址”,输入需删除的页面URL,百度通常会在3-30天内处理删除请求,期间可检查搜索结果确认是否生效,若页面已不存在,建议返回404状态码,加速删除流程。