防止百度抓取是网站运营和SEO优化中常见的需求,通常出于内容保护、避免重复收录、控制页面权重分配或调整网站结构等目的,要实现这一目标,需结合技术手段、平台规则和内容策略,以下是具体方法和注意事项:

使用robots.txt文件控制抓取范围
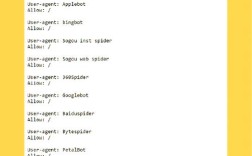
robots.txt是网站与搜索引擎爬虫沟通的“门禁文件”,通过它可明确禁止百度爬虫抓取特定目录或页面,需注意,robots.txt仅对规范的爬虫有效,恶意抓取无法完全阻止,且错误配置可能导致重要页面被误封,正确写法示例:
User-agent: Baiduspider
Disallow: /admin/ # 禁止抓取管理后台
Disallow: /temp/ # 禁止抓取临时目录
Allow: /public/ # 允许抓取公共目录关键点:
- 需上传至网站根目录(如
https://example.com/robots.txt); - 使用通配符可批量控制(如
Disallow: /*.php$禁止所有PHP页面); - 定期通过百度搜索资源平台检测robots.txt解析状态,避免语法错误。
设置Meta Robots标签
对于单个页面,可在HTML头部添加<meta name="robots" content="noindex,nofollow">标签,
noindex:禁止百度收录页面内容(页面仍可能被抓取,但不展示在搜索结果中);nofollow:禁止爬虫通过该页面的链接继续抓取其他页面。
适用场景:动态生成的页面(如搜索结果页)、用户隐私页面或未完善的内容页,需注意,该标签仅对HTML页面有效,无法控制图片、视频等非文本资源抓取。
通过服务器配置返回HTTP头指令
在服务器层面设置X-Robots-Tag响应头,可实现对非HTML资源的控制。

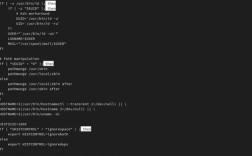
- Nginx配置:
location /private/ { add_header X-Robots-Tag "noindex, noarchive"; } - Apache配置:
<FilesMatch "\.(pdf|jpg)$"> Header set X-Robots-Tag "noindex, nofollow" </FilesMatch>
优势:可精准控制PDF、图片、CSS等文件类型,避免敏感资源被收录。
使用百度官方工具提交“死链”
若网站已存在不希望被收录的页面(如下线商品页、失效链接),可通过百度搜索资源平台将URL提交为“死链”,百度会逐步减少对这些页面的抓取,操作步骤:
- 登录百度搜索资源平台,选择“死链提交”;
- 上传包含死链URL的TXT文件(每行一个链接,编码为UTF-8);
- 确保死链文件可通过
http://域名/死链文件.txt直接访问。
登录百度搜索资源平台进行站点管理
在百度搜索资源平台验证网站所有权后,可进行更精细的控制:
- 抓取诊断:模拟百度爬虫抓取页面,检查是否存在误封或配置错误;
- 抓取频率设置:根据服务器承受能力调整百度爬虫的抓取强度(需谨慎操作,过高可能导致服务器负载过大);
- 网站改版:通过“网站改版”工具提交新旧URL对应关系,避免因结构调整导致收录丢失。
技术手段:动态内容与权限控制
- 登录后可见内容:将敏感内容(如用户个人中心、付费资源)设置为需登录后访问,百度爬虫因无法模拟登录而无法抓取;
- AJAX加载内容:通过异步加载动态内容,避免初始HTML中包含完整信息(但需注意百度对部分AJAX内容的抓取能力正在提升);
- IP黑白名单:通过服务器防火墙或CDN配置,限制百度爬虫的IP段访问(需谨慎,可能影响正常收录)。
内容策略:从源头减少抓取价值
百度爬虫优先抓取高价值内容,若页面缺乏原创性、用户体验差或更新频率低,即使未被robots.txt禁止,也可能被自然“放弃”,可通过以下方式降低抓取欲望:

- 减少低质量页面数量(如空页面、测试页); 添加访问提示(如“本内容需授权访问”);
- 定期清理死链和重复内容。
常见误区与注意事项
- robots.txt≠禁止收录:仅禁止抓取,若页面已被外部链接引用,仍可能被百度通过其他方式收录;
- 避免全站禁止:全站设置
Disallow: /会导致百度完全放弃网站,不利于后续SEO; - 验证配置有效性:使用百度搜索资源平台的“抓取诊断”或第三方工具(如 Screaming Frog)验证设置是否生效;
- 关注百度算法更新:百度会逐步提升对动态内容、JavaScript渲染页面的抓取能力,需定期调整策略。
相关问答FAQs
Q1: 为什么设置了robots.txt禁止抓取,页面仍被百度收录?
A: robots.txt仅禁止爬虫抓取页面内容,若页面已被其他网站链接引用,百度可能通过“百度快照”或外部链接间接收录该页面,恶意爬虫或违规平台可能无视robots.txt直接抓取,彻底解决需结合Meta标签的noindex去重。
Q2: 如何判断百度是否已停止抓取某个页面?
A: 可通过以下方式综合判断:
- 在百度搜索框使用
site:域名 页面URL指令,若未显示结果,通常表示未被收录; - 查看百度搜索资源平台的“索引量”数据,对比页面是否在统计范围内;
- 使用站长工具(如Ahrefs)检查页面外链是否减少(若百度停止抓取,外部导出链接可能逐渐消失);
- 观察服务器日志中是否还有来自百度的爬虫访问记录(如User-agent为
Baiduspider的请求)。
方法需结合使用,单一手段可能存在局限性,建议优先通过官方平台管理,并定期监控网站抓取与收录状态,根据需求动态调整策略。