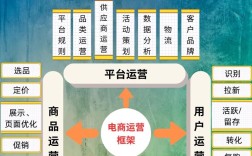
mahout 命令是 Apache Mahout 机器学习库的核心组成部分,它提供了一套简洁高效的命令行工具,让开发者无需编写复杂的代码即可快速实现数据预处理、模型训练、预测等常见机器学习任务,Mahout 最初专注于可扩展的机器学习算法实现,后来逐渐演变为一个支持多种计算引擎(如 Hadoop、Spark、Flink)的通用机器学习平台,其命令行工具也因此具备了灵活性和扩展性,适用于不同规模的数据处理需求。

数据预处理命令
在机器学习项目中,数据预处理往往是至关重要的一步,Mahout 提供了多个命令来处理原始数据,包括数据清洗、格式转换、特征提取等。mahout seqdirectory 命令可以将文本目录转换为 SequenceFile 格式,这是一种 Hadoop 优化的二进制存储格式,适合后续的分布式处理,而 mahout seq2sparse 命令则可以将 SequenceFile 数据转换为稀疏向量格式,同时支持 TF-IDF 权重计算、词干提取等文本特征处理操作,对于结构化数据,mahout vectors 命令提供了多种向量转换方法,如将 CSV 数据转换为 Mahout 支持的向量格式,并支持归一化、标准化等特征缩放操作。mahout split 命令可以方便地将数据集划分为训练集和测试集,比例为默认的 80:20,也可通过参数自定义比例,为模型训练和评估提供数据支持。
分类与聚类命令
分类和聚类是监督学习和无监督学习的典型任务,Mahout 提供了丰富的命令来支持这些场景,在分类任务中,mahout trainnb 命令基于朴素贝叶斯算法训练分类模型,输入为训练集的向量文件和类别标签,输出为训练好的模型文件,训练完成后,使用 mahout testnb 命令可以对测试集进行预测,并输出分类准确率、混淆矩阵等评估指标,除了朴素贝叶斯,Mahout 还支持随机森林、逻辑回归等算法,通过 mahout run 命令可以调用这些算法,mahout run -algo RandomForest -train input/train -model output/model,在聚类任务中,K-Means 是最常用的算法,mahout kmeans 命令可以快速执行聚类操作,需要指定初始聚类中心(可通过 mahout kmeansinit 生成)、距离度量(如欧氏距离、余弦相似度)和迭代次数,对于大规模数据,Mahout 还提供了 Canopy 聚类作为预处理步骤,mahout canopy 命令可以快速划分初始簇,减少 K-Means 的计算复杂度。
推荐系统命令
推荐系统是 Mahout 的传统优势领域,其命令行工具支持多种推荐算法,基于用户的协同过滤(User-Based CF)可以通过 mahout recommenditembased 命令实现,输入为用户-物品评分矩阵,输出为推荐结果列表,支持调整相似度计算方法(如皮尔逊相关系数、余弦相似度),基于物品的协同过滤(Item-Based CF)则通过 mahout itemrecommend 命令调用,通常适用于物品数量少于用户数量的场景,计算效率更高,对于矩阵分解算法,Mahout 提供了 mahout svd 命令进行奇异值分解,可以捕捉用户和物品的隐含特征,生成更精准的推荐结果。mahout dfcc 命令支持分布式过滤协同聚类,能够同时处理用户和物品的聚类,适用于稀疏数据场景。
模型评估与命令组合
Mahout 的命令不仅可以独立使用,还可以通过管道(Pipe)组合起来实现复杂的工作流,一个完整的文本分类流程可以组合为:mahout seqdirectory -i text -d seqfiles && mahout seq2sparse -i seqfiles -o sparsevector && mahout split -i sparsevector -o train:test -trainPct 80 && mahout trainnb -i train -o model && mahout testnb -i test -m model -o result,这种命令组合方式大大简化了机器学习流程的实现,在模型评估方面,除了分类任务的准确率、召回率等指标,Mahout 还提供了 mahout clusterdump 命令用于输出聚类结果的详细信息,包括簇中心、簇大小、簇内样本等,方便分析聚类效果。

相关问答FAQs
Q1:Mahout 命令与 Spark MLlib 有什么区别?
A1:Mahout 和 Spark MLlib 都是机器学习工具,但定位不同,Mahout 最初设计为基于 Hadoop 的分布式机器学习库,命令行工具是其特色,适合处理超大规模数据(TB 级别),且支持多种计算引擎(如 Hadoop、Spark),Spark MLlib 则是 Spark 生态的一部分,基于 Spark 的 RDD/DataFrame 实现,与 Spark 的流处理、图计算等组件无缝集成,API 更符合 Spark 用户的编程习惯,对于中小规模数据,Spark MLlib 的开发效率更高;而对于需要灵活命令行操作的超大规模数据场景,Mahout 更具优势。
Q2:如何解决 Mahout 命令执行时的内存不足问题?
A2:Mahout 命令执行内存不足通常与数据规模或 JVM 配置有关,可通过以下方式解决:1)增加 JVM 堆内存,例如在命令后添加 -Dmapred.child.java.opts=-Xmx4g 参数将内存设置为 4GB;2)使用分布式计算引擎(如 Spark 或 Hadoop),将任务拆分为多个子任务并行执行;3)调整 Mahout 的并行度,如通过 -Dmapreduce.job.reduces=10 设置 Reduce 任务数量;4)对数据进行采样或分块处理,减少单次处理的数据量,如果问题依然存在,可检查数据格式是否正确,避免因格式错误导致内存异常占用。