在当前互联网行业快速发展的背景下,数据已成为企业决策的核心资源,而爬虫技术作为数据获取的重要手段,其人才需求持续旺盛,Java凭借其强大的生态、稳定性和跨平台特性,在爬虫开发领域占据重要地位,许多企业在招聘Java爬虫工程师时,既关注候选人的技术深度,也重视其实战经验与问题解决能力,以下从岗位需求、核心技能、薪资水平及发展路径等方面,对Java爬虫招聘市场进行详细分析。

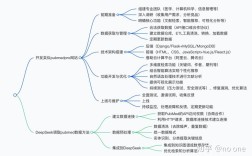
岗位需求与职责分布
Java爬虫工程师的岗位名称多样,包括“数据采集工程师”“爬虫开发工程师”“大数据开发工程师(数据方向)”等,职责根据企业规模和行业特点有所差异,从招聘要求来看,岗位需求主要集中在以下几个领域:
- 互联网与电商行业:如电商平台需要爬取竞品价格、用户评价,社交媒体平台需要抓取公开内容进行舆情分析,这类岗位通常要求候选人熟悉反爬机制应对,能够处理高并发数据采集。
- 金融科技行业:企业需爬取宏观经济数据、行业报告、金融市场信息等,对数据的准确性和实时性要求较高,岗位常强调候选人具备数据处理与分析能力。
- 人力资源与咨询行业:通过爬取招聘网站、企业公开信息进行市场调研或人才趋势分析,要求候选人熟悉数据清洗与结构化存储。
- 技术驱动型企业:部分公司将爬虫技术应用于搜索引擎优化、自动化测试等场景,需要候选人具备全栈开发能力,能够将爬虫系统与业务流程深度整合。
核心技能要求
企业在招聘Java爬虫工程师时,通常会从技术基础、爬虫框架、反爬应对、数据处理及工程化能力五个维度考察候选人,具体要求如下:
(一)技术基础
- Java语言能力:熟练掌握Java基础(集合、多线程、IO/NIO)、JVM原理,熟悉Java 8+新特性(如Stream API、Lambda表达式),能够编写高性能、低耦合的代码。
- 网络知识:深入理解HTTP/HTTPS协议,熟悉TCP/IP模型、Cookie与Session机制、代理原理,能够抓包分析请求流程(常用工具:Fiddler、Charles)。
- 数据库技能:掌握SQL语句编写,熟悉关系型数据库(MySQL、PostgreSQL)与非关系型数据库(MongoDB、Redis)的操作,能够设计高效的数据存储方案。
(二)爬虫框架与工具
- 主流框架:熟练使用HttpClient、Jsoup等基础工具,掌握至少一种专业爬虫框架,如WebMagic(基于Scrapy的Java实现)、Selenium(用于动态页面渲染)、Crawler4j等。
- 动态页面处理:能够结合HtmlUnit、PhantomJS等工具解决JavaScript渲染问题,或通过Selenium WebDriver模拟浏览器行为。
- 分布式爬虫:熟悉Scrapy-Redis、WebMagic-Redis等分布式方案,理解去重策略(BloomFilter)、URL调度机制,能够设计支持大规模数据采集的分布式架构。
(三)反爬应对与合规性
- 反爬突破:掌握IP代理池构建(如使用Socks5、HTTPS代理)、User-Agent池轮换、验证码识别(OCR技术如Tesseract、第三方接口如打码平台)、请求频率控制等技巧。
- 合规意识:熟悉《网络安全法》《数据安全法》等相关法规,能够编写Robots.txt解析逻辑,尊重网站robots协议,避免对目标服务器造成过大压力。
- 加密参数处理:能够通过抓包分析加密请求(如AES、RSA加密),使用Java实现逆向解密逻辑(常见于电商、社交平台)。
(四)数据处理与存储
- 数据清洗:熟练使用正则表达式、Jsoup、JsoupX等工具提取和清洗结构化、半结构化数据,能够处理HTML乱码、格式异常等问题。
- 数据存储:掌握文件存储(CSV、JSON、Excel)、数据库存储(MySQL分表分库、MongoDB分片集群)及大数据组件(Hadoop、Spark)的应用,根据业务需求选择合适的存储方案。
- 数据管道:熟悉Kafka、RabbitMQ等消息队列,能够设计高可用、可扩展的数据传输与处理管道。
(五)工程化与运维能力
- 版本控制:熟练使用Git进行代码管理,了解分支管理策略(如Git Flow)。
- 容器化与部署:掌握Docker容器化技术,能够使用Docker Compose部署爬虫服务,了解Kubernetes(K8s)的基本操作。
- 监控与日志:熟悉ELK(Elasticsearch、Logstash、Kibana)日志分析系统,能够使用Prometheus+Grafana进行监控,实现爬虫任务的自动化运维。
薪资水平与地域差异
Java爬虫工程师的薪资受地域、企业规模、工作经验及技能深度影响较大,以下为国内主要城市的薪资参考范围(月薪,含五险一金):
| 城市 | 应届生(0-2年) | 中级(3-5年) | 高级(5年以上) |
|---|---|---|---|
| 一线城市 | 8K-15K | 15K-30K | 30K-50K+ |
| 新一线城市 | 6K-12K | 12K-25K | 25K-40K+ |
| 二三线城市 | 4K-8K | 8K-18K | 18K-30K+ |
注:一线城市(北京、上海、广州、深圳)薪资水平最高,金融科技、互联网大厂的高级岗位年薪可达50万元以上;新一线城市(杭州、成都、武汉等)近年来薪资涨幅明显,部分企业为吸引人才提供额外项目奖金;二三线城市岗位较少,薪资相对较低,但生活成本优势明显。

职业发展路径
Java爬虫工程师的职业发展通常分为技术专家与管理两条路径:
- 技术专家路线:初级工程师→中级工程师(负责复杂爬虫系统开发)→高级工程师(设计分布式架构、攻克反爬技术)→技术专家(制定数据采集战略、攻克行业难题)。
- 管理路线:开发工程师→技术组长(带领5-10人团队)→技术经理(负责项目规划与资源协调)→技术总监(统筹数据采集体系建设)。
具备爬虫与大数据技术复合能力的工程师,可向数据工程师、算法工程师(如数据预处理方向)转型;熟悉业务场景的工程师可进入产品经理岗位,推动数据驱动的产品创新。
企业招聘关注点
企业在招聘Java爬虫工程师时,除上述技能要求外,还重点关注以下特质:
- 项目经验:有大型爬虫项目(如日采集千万级数据)或高并发系统开发经验者优先,候选人需在简历中明确描述项目规模、技术难点及解决方案。
- 学习能力:反爬技术迭代迅速,企业倾向于招聘具备快速学习能力的候选人,能够跟进最新的加密算法、反爬策略。
- 问题解决能力:通过笔试或面试中的场景题(如“如何应对动态IP封禁?”“如何设计亿级URL去重系统?”)考察候选人分析问题与设计解决方案的能力。
- 沟通协作:爬虫项目常需与产品、算法、运维团队协作,良好的沟通能力与团队意识是重要加分项。
相关问答FAQs
Q1:Java爬虫工程师需要掌握哪些反爬技术?
A1:反爬技术是爬虫开发的核心能力,主要包括:(1)IP代理:使用代理IP池(如付费代理服务商、自建代理服务器)避免单一IP被封;(2)请求伪装:随机User-Agent、模拟浏览器Headers(如Referer、Origin)、使用Cookie池管理登录状态;(3)验证码处理:简单验证码可通过OCR(如Tesseract)识别,复杂验证码(如滑动拼图、点选文字)需对接打码平台(如打码兔、超级鹰);(4)动态参数:通过抓包分析JS加密逻辑(如使用Charles或Fiddler拦截请求),在Java中逆向实现加密算法(如AES、MD5加盐);(5)行为模拟:使用Selenium模拟人工操作(如随机滑动鼠标、延迟点击),避免被识别为爬虫。

Q2:如何提升Java爬虫的采集效率?
A2:提升采集效率需从架构设计、代码优化、资源调度三方面入手:(1)分布式架构:采用Master-Worker模式,使用ZooKeeper或Redis实现任务调度与节点管理,通过多机并行采集提升吞吐量;(2)异步与并发:使用Java并发包(如ExecutorService线程池、CompletableFuture)实现异步请求,合理设置线程数(避免过多线程导致CPU或内存瓶颈);(3)连接池优化:使用HttpClient连接池(如PoolingHttpClientConnectionManager)复用TCP连接,减少握手开销;(4)数据存储优化:采用批量插入(如JDBC的addBatch)替代单条插入,使用内存缓存(如Guava Cache)减少磁盘IO;(5)智能调度:根据目标网站响应时间动态调整请求间隔,实现“慢速爬取”避免触发反爬,同时结合优先级队列(如PriorityQueue)优先采集高价值数据。