在数字化时代,获取招聘信息的方式已从传统的线下招聘会转向线上平台的高效触达,掌握正确的下载方法能帮助求职者快速筛选岗位、精准投递简历,以下是关于下载招聘信息的详细步骤、工具选择及注意事项,涵盖主流平台、特殊场景处理及数据管理技巧,助你高效获取目标岗位信息。

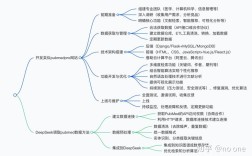
明确招聘信息来源与下载需求
下载招聘信息前,需先确定信息来源,主流招聘平台包括综合类(如智联招聘、前程无忧、BOSS直聘)、垂直类(如拉勾网互联网行业、猎聘高端岗位)、企业官网(如腾讯、阿里招聘专栏)及政府平台(如各地人社局官网“就业服务”板块),不同平台的信息格式、下载权限及使用场景存在差异,
- 综合类平台:岗位数量多,适合广泛投递,但需注意筛选无效信息;
- 垂直类平台:行业针对性强,岗位描述更精准,适合明确职业方向的求职者;
- 企业官网:可获取最新校招/社招动态,但需手动逐条整理;
- 政府平台:以事业单位、国企岗位为主,信息权威但更新较慢。
根据需求明确“下载目的”:若为批量筛选岗位,需支持表格导出;若为长期跟踪某企业招聘,需设置订阅提醒;若为避免重复投递,需标记已申请岗位。
主流招聘平台招聘信息下载方法
(一)综合类平台:智联招聘、前程无忧
-
岗位搜索与筛选
登录平台后,在搜索框输入关键词(如“产品经理”“北京”),通过“薪资范围”“工作经验”“学历”等条件筛选目标岗位,筛选结果页支持“最新发布”“相关度”排序,优先选择近期发布的岗位(通常时效性更强)。 -
单岗位信息保存
点击具体岗位进入详情页,可通过以下方式保存: (图片来源网络,侵删)
(图片来源网络,侵删)- 浏览器收藏:点击浏览器收藏夹,新建文件夹分类存储(如“互联网-产品岗”),便于后续查找;
- 截图保存:使用电脑自带截图工具(Win系统为“Win+Shift+S”,Mac为“Command+Shift+4”)截取岗位描述、要求及薪资信息,重命名后存入本地文件夹(建议格式:“企业名-岗位名-发布日期”);
- 复制粘贴:全选岗位详情(Ctrl+A/Ctrl+C),粘贴至Word或记事本,保留关键信息(删除平台广告等无关内容)。
-
批量岗位导出(需会员权限)
部分平台提供“批量导出”功能,需开通会员:- 智联招聘:筛选结果页点击“导出”,选择“Excel格式”,包含岗位名称、企业、薪资、工作地点等字段,导出后可通过Excel筛选(如用“数据-筛选”功能按“薪资>15k”过滤);
- 前程无忧:在“职位搜索结果”页点击“下载职位”,登录后选择导出范围(当前页/全部结果),生成表格文件,支持用Excel“分列”功能整理混乱的文本数据。
(二)垂直类平台:拉勾网、猎聘
-
拉勾网(互联网行业)
- 免费导出:搜索结果页点击“工具箱”,选择“导出职位”,支持导出当前页岗位(最多50条),包含岗位名称、公司、薪资、标签等,可直接用Excel打开;
- 会员批量导出:开通会员后,可导出全部搜索结果(最多1000条),并通过“历史记录”功能查看已导出记录,避免重复下载。
-
猎聘(高端/稀缺岗位)
- 岗位订阅:在搜索结果页点击“订阅”,设置关键词(如“算法工程师”)和更新频率,系统会通过邮件推送新岗位,点击邮件链接即可查看详情;
- 简历投递关联:投递岗位后,可在“投递记录”中查看已申请岗位详情,支持“标记已读/未读”,避免重复投递。
(三)企业官网招聘信息下载
-
手动整理法
进入企业官网“招贤纳士”或“加入我们”板块,逐条查看岗位信息,使用“复制粘贴”或截图保存,建议按企业分类建立文件夹(如“互联网企业-腾讯”“制造业-海尔”)。 (图片来源网络,侵删)
(图片来源网络,侵删) -
RSS订阅工具(适合技术型用户)
部分企业官网提供RSS订阅源(如网易招聘RSS:https://hr.163.com/rss/jobs.xml),通过浏览器插件(如“Feedly”“Inoreader”)订阅,新岗位会自动同步至阅读器,支持一键导出为Markdown或HTML格式。 -
自动化脚本(需基础编程能力)
使用Python的requests和BeautifulSoup库编写爬虫,自动抓取官网岗位信息(示例代码片段):import requests from bs4 import BeautifulSoup import pandas as pd url = "https://company.com/jobs" response = requests.get(url) soup = BeautifulSoup(response.text, "html.parser") jobs = soup.find_all("div", class_="job-item") # 根据实际网页结构调整 data = [] for job in jobs: title = job.find("h3").text desc = job.find("p").text data.append([title, desc]) df = pd.DataFrame(data, columns=["岗位名称", "岗位描述"]) df.to_excel("company_jobs.xlsx", index=False) # 导出为Excel注意:爬虫需遵守网站
robots.txt协议,避免高频请求导致IP被封,建议添加延时(如time.sleep(2))。
特殊场景:招聘信息下载进阶技巧
(一)非公开岗位获取(内推/猎头渠道)
- 内推信息:通过LinkedIn、脉脉等平台联系目标企业员工,请求对方转发岗位JD(Job Description),接收后需手动整理至个人岗位库;
- 猎头推送:猎头通常通过微信或邮件发送岗位信息,建议在微信中“收藏”消息(添加标签“目标岗位”),邮件则通过“规则分类”存入“招聘信息”文件夹。
(二)跨平台数据整合
使用Excel或Notion建立个人岗位管理表,统一字段包括:岗位名称、企业名称、薪资范围、工作地点、投递状态(未投递/已投递/面试中)、截止日期等,示例表格如下:
| 岗位名称 | 企业名称 | 薪资范围 | 工作地点 | 投递状态 | 截止日期 | 备注 |
|---|---|---|---|---|---|---|
| 产品经理 | 字节跳动 | 20-35k | 北京 | 已投递 | 2023-12-31 | 需3年经验,有算法背景 |
| 数据分析师 | 美团 | 15-25k | 上海 | 未投递 | 2024-01-15 | 优先SQL/Python技能 |
(三)避免重复下载与信息过时
- 定期清理:每周整理岗位文件夹,删除已投递或已失效岗位(可通过“发布日期”判断,超过1个月的岗位可能已关闭);
- 设置标签:在文件管理工具(如百度网盘、阿里云盘)中为岗位文件添加标签(如“急招”“应届生”“远程”),快速定位优先级高的岗位。
注意事项:合规性与信息保护
- 遵守平台规则:部分平台禁止爬虫批量下载(如BOSS直聘),若需导出大量数据,建议开通官方会员,避免账号被封禁;
- 保护个人隐私:下载的岗位信息中可能包含企业联系方式,勿随意泄露给第三方,防止信息被滥用;
- 核实信息真实性:非官方渠道(如微信群、论坛)的招聘信息需通过“天眼查”“企查查”核实企业资质,警惕虚假招聘。
相关问答FAQs
Q1:为什么在招聘平台导出岗位信息时提示“权限不足”?
A:多数平台限制免费用户批量导出数据,这是其会员权益的一部分,解决方法包括:①开通平台会员(如智联招聘“钻石会员”、前程无忧“简历优先会员”);②使用免费替代方案,如手动复制当前页岗位信息(最多50条),或通过第三方工具“网页另存为”后提取文本。
Q2:如何高效管理下载的大量招聘信息?
A:建议采用“分类标签+定期更新”的管理模式:①按行业/企业类型建立文件夹(如“互联网-运营”“制造业-机械”),每个文件夹内按“投递状态”分文件夹(未投递/已投递/面试中);②使用Excel或Notion创建岗位追踪表,记录投递时间、反馈进展等关键信息;③每周清理一次,删除已过期或已放弃的岗位,保持信息库更新。