Hadoop配置命令是搭建和管理Hadoop集群的核心操作,涉及集群初始化、节点管理、服务启停、参数调优等多个环节,以下从集群环境准备、核心配置文件解析、常用管理命令、高可用配置及安全配置五个方面,详细说明Hadoop的配置命令及操作逻辑。

集群环境准备
在配置Hadoop前,需完成基础环境搭建,包括操作系统(推荐Linux CentOS 7+)、JDK安装(需JDK 1.8+)、SSH免密登录配置及主机名与IP映射,通过ssh-keygen生成密钥对,并将公钥分发至各节点:ssh-copy-id hadoop@node1,随后,在/etc/hosts文件中添加所有节点的主机名与IP映射,确保节点间通信无障碍,需创建Hadoop专用用户(如hadoop)并配置sudo权限,避免root用户操作风险。
核心配置文件解析
Hadoop的配置文件位于$HADOOP_HOME/etc/hadoop目录下,需根据集群规模和业务需求调整关键参数,以下为核心配置文件及其命令示例:
-
core-site.xml:配置Hadoop核心属性,如文件系统默认地址、临时目录等。
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://cluster1</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/tmp</value> </property> </configuration> -
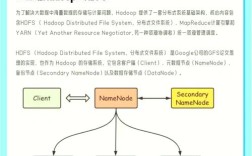
hdfs-site.xml:配置HDFS相关参数,如副本数、数据存储目录、NameNode高可用等。
 (图片来源网络,侵删)
(图片来源网络,侵删)<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/data/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/data/hadoop/dfs/data</value> </property> </configuration> -
mapred-site.xml:配置MapReduce框架,通常设置为YARN模式。
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
yarn-site.xml:配置YARN资源管理参数,如NodeManager资源、日志聚合等。
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> </configuration> -
workers(或
slaves):列出所有DataNode和NodeManager节点的主机名,每行一个。node1 node2 node3
配置完成后,需将配置文件同步至所有节点,可通过scp命令实现:scp -r /opt/hadoop/etc/hadoop hadoop@node2:/opt/hadoop/。

常用管理命令
Hadoop提供了丰富的命令行工具用于集群管理,以下为高频操作命令:
-
HDFS初始化(首次启动前执行):
hdfs namenode -format
注意:格式化NameNode会删除HDFS数据,仅在首次部署或需清空数据时执行。
-
集群服务启停:
- 启动HDFS:
start-dfs.sh - 停止HDFS:
stop-dfs.sh - 启动YARN:
start-yarn.sh - 停止YARN:
stop-yarn.sh - 查看进程状态:
jps(NameNode、DataNode、ResourceManager、NodeManager等进程需正常运行)
- 启动HDFS:
-
HDFS文件操作:
- 创建目录:
hdfs dfs -mkdir /input - 上传文件:
hdfs dfs -put local.txt /input/ - 查看文件:
hdfs dfs -cat /input/local.txt - 查看磁盘使用:
hdfs dfs -df -h
- 创建目录:
-
YARN任务管理:
- 提交MapReduce任务:
hadoop jar mapreduce-example.jar wordcount /input /output - 查看任务状态:
yarn application -list - 杀死任务:
yarn application -kill <application_id>
- 提交MapReduce任务:
-
节点维护:
- 进入安全模式(维护HDFS):
hdfs dfsadmin -safemode enter - 退出安全模式:
hdfs dfsadmin -safemode leave - 添加DataNode:将新节点加入
workers文件后,在节点上启动hadoop-daemon.sh start datanode,并在NameNode节点执行hdfs dfsadmin -refreshNodes。
- 进入安全模式(维护HDFS):
高可用配置
Hadoop 2.x及以上版本支持HDFS和YARN的高可用(HA),需通过ZooKeeper实现故障转移,以HDFS HA为例,配置步骤如下:
-
修改core-site.xml:添加ZooKeeper集群地址和HA代理。
<property> <name>ha.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> <property> <name>ha.automatic-failover.enabled</name> <value>true</value> </property>
-
修改hdfs-site.xml:配置NameNode HA相关参数。
<property> <name>dfs.nameservices</name> <value>cluster1</value> </property> <property> <name>dfs.ha.namenodes.cluster1</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.cluster1.nn1</name> <value>node1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.cluster1.nn2</name> <value>node2:8020</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node1:8485;node2:8485;node3:8485/cluster1</value> </property>
-
初始化JournalNode:
hdfs --journalnode
在所有JournalNode节点启动服务后,在其中一个NameNode节点执行:
hdfs namenode -initializeSharedEdits -force
-
启动HA集群:
- 启动JournalNode:
hdfs --journalnode - 格式化并启动Active NameNode:
hdfs namenode -format,hadoop-daemon.sh start namenode - 启动Standby NameNode:
hdfs namenode -bootstrapStandby,hadoop-daemon.sh start namenode - 启动ZKFC:
hdfs zkfc -formatZK,hadoop-daemons.sh start zkfc
- 启动JournalNode:
安全配置
为保障集群安全,需启用Kerberos认证和ACL权限控制,以Kerberos为例,步骤如下:
-
创建Kerberos主体:
kadmin -q "addprinc -randkey hadoop/node1@EXAMPLE.COM" kadmin -q "ktadd -k /etc/hadoop/conf/hadoop.keytab hadoop/node1@EXAMPLE.COM"
-
修改core-site.xml:启用安全认证。
<property> <name>hadoop.security.authentication</name> <value>kerberos</value> </property> <property> <name>hadoop.keytab.file</name> <value>/etc/hadoop/conf/hadoop.keytab</value> </property>
-
启动安全集群:
kinit -kt /etc/hadoop/conf/hadoop.keytab hadoop/node1@EXAMPLE.COM start-dfs.sh start-yarn.sh
相关问答FAQs
问题1:Hadoop集群启动后DataNode无法连接NameNode,如何排查?
解答:首先检查/var/log/hadoop/hadoop-hdfs-datanode.log日志,常见原因包括:
- 网络问题:确保
workers文件中的主机名与/etc/hosts一致,节点间ping通。 - 防火墙:关闭防火墙或开放HDFS端口(默认8020、9000等)。
- 权限问题:确保DataNode节点有权限访问NameNode的存储目录。
- 配置错误:检查
core-site.xml中fs.defaultFS是否指向正确的NameNode地址。
问题2:YARN任务运行失败,提示“Container is running beyond virtual memory limits”,如何解决?
解答:该错误通常因任务内存超限导致,可通过调整YARN内存参数解决:
- 修改
yarn-site.xml,增加容器内存限制:<property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>8192</value> </property>
- 重启YARN服务:
stop-yarn.sh && start-yarn.sh。 - 提交任务时指定内存:
-Dmapreduce.map.memory.mb=4096 -Dmapreduce.reduce.memory.mb=4096。