要让网站不被搜索引擎收录,需要从技术配置、内容策略、服务器设置等多个维度进行系统性干预,搜索引擎的收录机制依赖于爬虫抓取、索引解析和排名展示三个环节,阻断其中任一环节都能实现“不收录”的目标,以下是具体操作方法及注意事项,涵盖从基础设置到高级控制的全方位指南。

核心控制文件配置
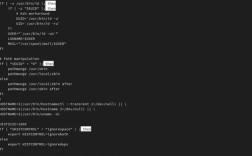
robots.txt是搜索引擎爬虫访问网站时的第一道指令,通过合理配置可限制爬虫抓取范围,需在网站根目录下创建纯文本文件,语法遵循Robot Exclusion Protocol标准,基础配置示例:
User-agent: *
Disallow: / # 完全禁止所有爬虫访问或精细控制:
User-agent: Googlebot
Disallow: /admin/
Disallow: /temp/
Crawl-delay: 5 # 设置抓取延迟注意事项:robots.txt仅能建议爬虫遵守,恶意爬虫可能忽略该文件;且禁止收录的路径仍可能被手动提交至搜索引擎,需配合其他措施。
Meta标签与HTTP头控制
在HTML页面的<head>部分添加robots元标签,可针对单页面设置收录规则:

<meta name="robots" content="noindex,nofollow">
参数说明:
noindex:禁止搜索引擎索引该页面nofollow:禁止爬虫跟踪页面上的链接noarchive:禁止缓存页面内容nosnippet:禁止展示页面摘要
对于动态生成页面,可通过服务器设置HTTP响应头实现更严格的控制,例如在Nginx配置中添加:
add_header X-Robots-Tag "noindex, nofollow";
或针对特定路径:
location /private/ {
add_header X-Robots-Tag "none";
}
搜索引擎站长工具设置
主流搜索引擎提供官方的收录控制入口,在Google Search Console、百度站长平台等工具中:

- 验证网站所有权后,进入“设置”→“抓取”
- 选择“抓取的网址”→“删除”
- 输入需要删除的URL,选择“因其他原因删除”
- 提交删除请求(通常需3-7天生效)
注意:此方法仅适用于已收录页面,对未收录页面无效;且删除后若重新抓取可能再次索引。
内容访问权限控制
通过技术手段限制非授权用户访问,搜索引擎爬虫也会被屏蔽:
- IP访问控制:在服务器层面(如.htaccess或防火墙)仅允许特定IP访问:
Order deny,allow Deny from all Allow from 192.168.1.0/24
- 登录验证:对整个网站或目录设置HTTP Basic认证:
AuthType Basic AuthName "Restricted Area" AuthUserFile /path/to/.htpasswd Require valid-user
- 动态访问令牌:通过Session或Cookie验证,未登录用户返回403状态码。
技术性屏蔽措施
- 返回403状态码:当爬虫访问时返回“禁止访问”的HTTP状态码,比404更明确表达拒绝意图。
- 使用CAPTCHA:对可疑爬虫展示验证码,主流搜索引擎爬虫通常不会处理验证码。
- JavaScript检测:通过JS检测用户行为(如鼠标移动、点击),仅对人类用户展示内容,但可能影响用户体验。
内容策略调整
- 动态生成内容存储在数据库中,通过AJAX异步加载,避免直接生成HTML页面。
- :将核心内容拆分为多个子资源,通过Canvas或WebGL动态渲染,搜索引擎难以解析。
- 轮换:频繁更新页面URL和内容,增加爬虫索引难度。
服务器与网络层控制
- CDN配置:在CDN层面设置爬虫黑名单,例如Cloudflare可通过“规则引擎”拦截特定User-Agent。
- DNS设置:将域名指向空IP或使用NXDOMAIN响应,但会导致网站完全无法访问。
- 带宽限制:对爬虫IP进行流量限制,例如使用iptables:
iptables -A INPUT -p tcp --dport 80 -m string --string "Googlebot" --algo bm -j DROP
常见错误规避
- 避免混合信号:不要同时使用robots.txt禁止和XML Sitemap提交,两者冲突可能导致搜索引擎忽略禁止指令。
- 测试验证:使用Google的“robots.txt测试工具”或百度“抓取诊断”验证配置有效性。
- HTTPS影响:确保HTTPS页面正确设置HSTS头,避免爬虫因证书问题无法访问。
长期维护建议
- 定期审计:每月检查网站收录情况,使用
site:domain.com指令监控搜索引擎索引状态。 - 日志分析:分析服务器访问日志,识别异常爬虫行为并调整屏蔽策略。
- 法律声明:在网站隐私政策中明确声明“禁止爬虫抓取”,增强法律保护依据。
特殊场景处理
| 场景 | 解决方案 | 注意事项 |
|---|---|---|
| 测试环境 | robots.txt禁止 + IP白名单 | 避免测试数据泄露 |
| 内部系统 | HTTP Basic认证 + VPN访问 | 确保认证安全性 |
| 临时页面 | 设置30天过期时间 + robots.txt | 过期后自动允许收录 |
通过上述组合措施,可有效控制搜索引擎的收录行为,需要根据网站类型和业务需求选择合适的方法组合,例如公开网站可通过robots.txt和meta标签控制,而内部系统则建议采用IP白名单+认证的双重保护,实施后需定期监控效果,确保策略持续有效。
相关问答FAQs
Q1: 使用robots.txt禁止收录后,已收录的页面多久会消失?
A: 搜索引擎处理时间因平台而异,Google通常需要数周至数月才会从搜索结果中移除robots.txt禁止的页面,而百度可能需要1-3个月,要加速此过程,可配合站长工具提交删除请求,或通过403状态码明确拒绝访问,但需注意,禁止收录仅影响搜索结果,页面缓存可能仍存在于搜索引擎服务器中。
Q2: 如果不小心设置了错误的robots.txt导致整个网站不被收录,如何快速恢复?
A: 立即编辑robots.txt文件,将Disallow: /修改为Allow: /或删除该规则,随后在Google Search Console中提交sitemap,并使用“请求编入索引”功能手动提交重要页面URL,百度站长平台可通过“URL提交”工具加速恢复,通常情况下,修正后1-2周内搜索引擎会重新抓取,但完全恢复搜索排名可能需要更长时间,建议在修改前先备份原始robots.txt文件。