下面我将从基础到高级,全面地介绍 grep 命令的用法。

基础用法
grep 的基本功能是在文件中搜索匹配的行,并将其打印到标准输出。
基本语法
grep [选项] '模式' 文件...
选项:用于控制grep的行为。模式:你想要搜索的字符串或正则表达式。文件:一个或多个要搜索的文件名。
最简单的例子
在 file.txt 文件中搜索包含 "hello" 的行。
grep 'hello' file.txt
区分大小写
默认情况下,grep 是区分大小写的。
# 只会匹配小写的 'world' grep 'world' file.txt
不区分大小写
使用 -i 选项可以忽略大小写。

# 会匹配 'World', 'WORLD', 'world' 等 grep -i 'world' file.txt
显示行号
使用 -n 选项可以在输出的每一行前面加上其在文件中的行号。
grep -n 'hello' file.txt
输出示例:
5:This is a hello world example.
10:Say hello to everyone.显示匹配行之外的所有行
使用 -v 选项可以反转查找,即输出不包含匹配模式的行。
# 显示 file.txt 中所有不包含 'hello' 的行 grep -v 'hello' file.txt
进阶用法
递归搜索目录
使用 -r 或 -R 选项可以递归地搜索指定目录下的所有文件。

# 在当前目录及其子目录的所有文件中搜索 'error' grep -r 'error' .
只显示文件名
当使用 -r 递归搜索多个文件时,默认会显示 文件名:匹配行,如果你只想显示包含匹配模式的文件名,可以使用 -l 选项。
# 只显示包含 'error' 的文件名 grep -r -l 'error' .
使用正则表达式
grep 默认支持基础正则表达式,元字符(如 ^, , 等)有特殊含义。
^:匹配行的开头。- 匹配行的结尾。
- 匹配任意单个字符。
- 匹配前一个字符零次或多次。
[]:匹配指定范围内的任意一个字符。
示例:
# 搜索所有以 "The" 开头的行 grep '^The' file.txt # 搜索所有以 "end." 结尾的行 grep 'end\.$' file.txt # 搜索包含 "gr[ae]y" 的行 (即 gray 或 grey) grep 'gr[ae]y' file.txt
使用扩展正则表达式
使用 -E 选项可以启用扩展正则表达式,它支持更多的元字符,如 , , , 等,并且不需要对 进行转义。
- 匹配前一个字符一次或多次。
- 匹配前一个字符零次或一次。
- 匹配 两边的任意一个表达式。
- 分组。
示例:
# 搜索包含 "apple" 或 "orange" 的行 (基础正则表达式需要用 grep -E 'apple\|orange') grep -E 'apple|orange' file.txt # 搜索包含 "colou?r" 的行 (即 color 或 colour) grep -E 'colou?r' file.txt
显示匹配次数
使用 -c 选项可以统计每个文件中匹配行的总数。
# 统计 file.txt 中包含 'hello' 的行数 grep -c 'hello' file.txt
只显示匹配的文本部分
使用 -o 选项可以只打印匹配到的部分,而不是整行。
# 只打印出所有匹配 'go+' 的部分 echo "I go to school, going to play." | grep -o 'go+'
输出:
go
going
go高级用法与技巧
排除特定文件
结合 --exclude 或 --exclude-dir 选项,可以在搜索时排除特定文件或目录。
# 递归搜索,但排除所有 .log 文件和 .git 目录 grep -r 'search_term' . --exclude='*.log' --exclude-dir='.git'
使用固定字符串模式
如果你搜索的字符串中包含很多正则表达式元字符(如 , , ),而你只想把它们当作普通字符来搜索,可以使用 -F 选项(Fixed strings)。
# 'file*' 中的 '*' 会被当作普通星号,而不是正则表达式的通配符 grep -F 'file*' file.txt
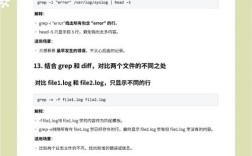
显示匹配前后的行
-B <num>:显示匹配行之前的num行(Before)。-A <num>:显示匹配行之后的num行(After)。-C <num>:显示匹配行前后的各num行(Context)。
这在查看日志时非常有用。
# 搜索 'error',并显示匹配行及其前后2行的内容 grep -C 2 'error' app.log
使用颜色高亮
使用 --color=auto 选项(很多系统 grep 默认已开启)可以用颜色高亮显示匹配的文本。
grep --color=auto 'error' app.log
匹配整词
使用 -w 选项可以确保匹配的是完整的单词,而不是单词的一部分。
# 只会匹配 'the',不会匹配 'then' 或 'weather' grep -w 'the' file.txt
通过管道传递数据
grep 的一个强大之处在于它可以从其他命令的输出中读取数据(通过管道符 )。
# 列出当前目录下所有以 'txt' 结尾的文件 ls -l | grep 'txt$' # 查看系统启动过程中的错误信息 dmesg | grep -i 'error'
常用选项速查表
| 选项 | 全称 | 说明 |
|---|---|---|
-i |
--ignore-case |
忽略大小写进行搜索。 |
-v |
--invert-match |
反转查找,只显示不匹配的行。 |
-n |
--line-number |
在输出中显示匹配行的行号。 |
-c |
--count |
只输出每个文件中匹配行的总数。 |
-l |
--files-with-matches |
只列出包含匹配项的文件名。 |
-L |
--files-without-match |
只列出不包含匹配项的文件名。 |
-h |
--no-filename |
在多文件搜索时,不显示文件名前缀。 |
-r / -R |
--recursive |
递归搜索目录下的所有文件。 |
-E |
--extended-regexp |
使用扩展正则表达式。 |
-F |
--fixed-strings |
将模式视为固定字符串(非正则表达式)。 |
-P |
--perl-regexp |
使用 Perl 兼容的正则表达式。 |
-o |
--only-matching |
只打印匹配到的部分。 |
-f |
--file=FILE |
从文件中读取模式列表,每行一个模式。 |
-q |
--quiet, --silent |
静默模式,不输出任何内容,通过退出状态码表示是否找到。 |
-w |
--word-regexp |
只匹配整个单词。 |
-x |
--line-regexp |
只匹配整行完全相同的行。 |
-B |
--before-context=NUM |
显示匹配行之前的 NUM 行。 |
-A |
--after-context=NUM |
显示匹配行之后的 NUM 行。 |
-C |
--context=NUM |
显示匹配行前后的各 NUM 行。 |
--color |
--colour=WHEN |
用颜色高亮匹配文本。auto 表示自动。 |
grep 是一个极其灵活的工具,掌握它的基本用法和常用选项,能极大地提高你在命令行下处理文本的效率,建议从 -i, -n, -v, -r 等基础选项开始练习,然后逐步学习正则表达式和更高级的上下文搜索功能。