太棒了!这是一个非常有挑战性但回报丰厚的项目,构建一个搜索网站,从简单的内部站内搜索到能挑战谷歌的全球搜索引擎,其复杂度天差地别。

(图片来源网络,侵删)
我会为你提供一个从易到难、循序渐进的完整指南,涵盖从技术选型到部署运营的全过程,你可以根据自己的兴趣、技术能力和资源,选择合适的切入点。
第一部分:明确你的目标和范围
在开始编码之前,最重要的一步是定义你的搜索引擎要做什么,这决定了你采用的技术架构和开发难度。
等级 1:站内搜索引擎
- 目标:为你的博客、公司官网或小型项目添加一个搜索框,只搜索你自己的网站内容。
- 技术:相对简单,有很多现成的解决方案。
- 适合人群:网站开发者、博主、小企业主。
等级 2:垂直领域搜索引擎
- 目标:专注于某一个特定领域,
- 学术搜索:搜索论文、期刊(如 Google Scholar)。
- 电商搜索:搜索商品(如 Amazon、淘宝)。
- 新闻搜索:搜索新闻资讯。
- 软件/代码搜索:搜索 GitHub 上的代码或开源项目。
- 技术:需要处理特定类型的数据,实现更复杂的排序和筛选。
- 适合人群:有特定领域需求的技术团队或创业者。
等级 3:通用网络搜索引擎
- 目标:像 Google、Bing 一样,索引整个互联网,为用户提供广泛的搜索服务。
- 技术:极其复杂,需要庞大的分布式系统、海量存储和强大的算法。
- 适合人群:拥有大型技术团队和雄厚资金的大公司或研究机构。(对个人或小团队来说,这是一个不切实际的目标,但我们依然可以了解其原理)
第二部分:搜索引擎的核心工作原理
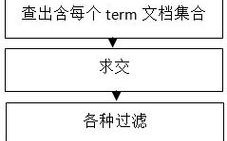
无论规模大小,所有搜索引擎都遵循三个基本步骤:
- 爬取:像一个蜘蛛一样,在互联网上发现并抓取网页。
- 索引:将抓取到的网页内容进行分析、处理,并存储在一个巨大的数据库(索引库)中,以便快速查找。
- 检索:当用户输入查询词时,在索引库中快速找到相关网页,并根据一定的排序算法(如 PageRank、TF-IDF 等)将结果呈现给用户。
我们将围绕这三个步骤来构建你的搜索引擎。

(图片来源网络,侵删)
第三部分:分步构建指南(以“站内搜索”和“垂直搜索”为例)
选择技术栈
对于初学者和中级开发者,强烈建议使用开源的搜索引擎框架,而不是从零开始造轮子。
| 技术栈 | 描述 | 优点 | 缺点 | 适合等级 |
|---|---|---|---|---|
| Elasticsearch | (强烈推荐) 基于 Lucene 的分布式、RESTful 风格的搜索和数据分析引擎。 | 功能强大、高性能、扩展性好、社区活跃、生态系统完善。 | 学习曲线较陡,需要理解一些核心概念(如倒排索引、分片)。 | 1, 2, 3 |
| Apache Solr | 也基于 Lucene,是一个独立的企业级搜索服务器。 | 成熟稳定、功能全面、可配置性高。 | 相比 Elasticsearch,配置更复杂,生态系统不如 ES 丰富。 | 1, 2 |
| Whoosh | 一个纯 Python 编写的搜索引擎库。 | 纯 Python,易于集成到 Python 项目中,无需外部服务。 | 性能和功能远不如 Elasticsearch,不适合大规模数据。 | 1 |
| Algolia | 一个托管的搜索即服务平台。 | 部署极其简单,速度极快,提供强大的 API。 | 付费服务,成本随数据量和查询量增长,定制化程度受限。 | 1, 2 |
建议:
- 学习/个人项目:从 Whoosh 开始,用纯 Python 体验搜索原理。
- 商业项目/垂直搜索:直接上 Elasticsearch,它是行业标准,能应对未来扩展。
详细实现流程(以 Elasticsearch 为例)
假设我们要做一个“技术博客”的垂直搜索引擎。
阶段 1:数据爬取
你需要一个程序(爬虫)去获取博客文章的数据。

(图片来源网络,侵删)
- 目标:获取每篇文章的 URL、标题、正文内容、发布时间、作者 等信息。
- 工具:
- Scrapy (Python):功能强大的爬虫框架,适合大规模数据抓取。
- Beautiful Soup / Requests (Python):轻量级库,适合简单的页面解析。
- 如果目标网站提供了 API(如 RSS feed),优先使用 API,更稳定、高效。
爬虫输出:一个包含文章信息的 JSON 文件列表,
[
{
"url": "https://myblog.com/post-1",: "如何学习 Elasticsearch",
"content": "Elasticsearch 是一个基于 Lucene 的搜索引擎...",
"author": "张三",
"publish_date": "2025-10-27"
},
...
]
阶段 2:数据索引
这是将爬取的数据存入 Elasticsearch 的过程。
- 安装 Elasticsearch:按照官方文档安装并运行 Elasticsearch 服务。
- 创建索引:在 ES 中,一个索引就像一个数据库表,你需要定义索引的结构(Mapping)。
title:设置为text类型,用于全文搜索。content:设置为text类型,并配置analyzer(分词器)为ik_max_word(中文分词)或standard(英文分词)。author,url:设置为keyword类型,用于精确匹配和排序。publish_date:设置为date类型,用于日期范围过滤。
- 数据导入:编写一个脚本,读取爬虫生成的 JSON 文件,通过 ES 的 REST API 将数据批量导入到索引中。
Python 示例代码 (使用 elasticsearch-py 库):
from elasticsearch import Elasticsearch
# 连接到 Elasticsearch
es = Elasticsearch(["http://localhost:9200"])
# 定义索引结构 (Mapping)
index_mapping = {
"mappings": {
"properties": {
"title": { "type": "text" },
"content": { "type": "text", "analyzer": "ik_max_word" }, # 使用中文分词器
"author": { "type": "keyword" },
"url": { "type": "keyword" },
"publish_date": { "type": "date" }
}
}
}
# 创建索引
es.indices.create(index="tech_blog", body=index_mapping)
# 模拟一条博客数据
blog_post = {: "如何建搜索网站",
"content": "构建搜索网站需要爬取、索引和检索三个步骤,Elasticsearch 是一个很好的选择。",
"author": "李四",
"url": "https://myblog.com/post-2",
"publish_date": "2025-10-28"
}
# 将数据索引到 Elasticsearch
es.index(index="tech_blog", id=1, document=blog_post)
阶段 3:搜索与展示
这是用户最终交互的部分。
- 构建前端界面:创建一个简单的 HTML 页面,包含一个搜索输入框和一个用于显示结果的区域。
- 后端 API:编写一个后端服务(可以用 Flask, Django, Node.js 等),它接收前端的搜索请求,然后向 Elasticsearch 发送查询。
- 执行查询:使用 ES 的查询语言(Query DSL),可以实现非常复杂的搜索逻辑。
- 基本查询:
match查询,在title和content字段中搜索用户输入的关键词。 - 高亮显示:将搜索结果中的关键词用
<em>标签高亮。 - 排序:按
publish_date降序排列最新的文章。 - 过滤:只显示特定作者的文章。
- 基本查询:
Python 查询示例:
# 假设用户搜索 "搜索网站"
query = {
"query": {
"multi_match": { # 在多个字段中搜索
"query": "搜索网站",
"fields": ["title^3", "content"] # title 字段的权重是 content 的 3 倍
}
},
"highlight": { # 高亮显示
"fields": {
"content": {}
}
},
"sort": [
{"publish_date": "desc"} # 按发布日期降序
]
}
# 执行搜索
results = es.search(index="tech_blog", body=query)
# 处理并返回结果给前端
for hit in results['hits']['hits']:
source = hit['_source']
highlights = hit.get('highlight', {}).get('content', [])
print(f"标题: {source['title']}")
print(f"链接: {source['url']}")
print(f"高亮内容: {highlights[0] if highlights else '无'}")
print("---")
第四部分:进阶与优化
当你完成了基础版本后,可以考虑以下优化,让搜索引擎更“智能”:
-
相关性排序:
- TF-IDF:衡量一个词对一篇文档的重要性。
- BM25:TF-IDF 的一个升级版,是目前效果较好的排序算法之一,Elasticsearch 默认使用它。
- PageRank:通过分析网页之间的链接关系,来判断网页的权威性(Google 的核心算法)。
-
自然语言处理:
- 同义词搜索:用户搜 "电脑",也能搜到 "计算机" 的结果。
- 拼写纠错:用户输 "searh",能自动纠正为 "search"。
- 搜索建议/自动补全:用户输入 "pyth",就能提示 "python", "python教程"。
-
分布式与高可用:
当数据量变大时,需要将 Elasticsearch 部署在多个服务器上,形成集群,通过分片和复制来保证性能和数据的可靠性。
-
持续爬取与更新:
是不断更新的,你需要设置一个定时任务(如 Cron Job),定期运行爬虫,抓取新内容或更新旧内容,并重新索引到 Elasticsearch 中。
第五部分:学习资源推荐
- Elasticsearch 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html (最好的学习资料)
- Scrapy 官方文档:https://scrapy.org/
- 在线课程:
- Coursera/edX 上有关于信息检索和搜索引擎的大学课程。
- Udemy 上有 "Elasticsearch: The Definitive Guide" 等实战课程。
- 书籍:
- 《Elasticsearch 权威指南》
- 《搜索引擎:信息检索实践》
构建一个搜索网站是一个系统工程,但完全可以从一个小的、可实现的目标开始。
给初学者的行动计划:
- 确定目标:先做一个站内搜索,为你自己的博客或一个你喜欢的网站做搜索。
- 搭建环境:在你的电脑上安装 Docker,然后通过 Docker 一键启动 Elasticsearch 和 Kibana (ES 的可视化工具)。
- 学习基础:花几天时间,跟着 Elasticsearch 官方文档的 "Getting Started" 教程,学习如何创建索引、导入数据、执行简单查询。
- 动手实践:用 Python + Scrapy 写一个简单的爬虫,抓取你目标网站的前 10 篇文章。
- 整合上线:用 Flask 或 Django 写一个后端,接收搜索请求并查询 ES;用 HTML/JS 写一个简单前端,展示结果。
- 迭代优化:尝试添加高亮、排序、分页等功能,逐步体验搜索引擎的强大。
祝你成功!这是一个充满挑战和乐趣的旅程。