制作一款自己的搜索工具是一个涉及技术选型、数据处理和用户体验设计的系统性工程,以下从核心步骤、技术实现和优化方向三个维度展开详细说明。

(图片来源网络,侵删)
明确需求与技术选型
首先需确定搜索场景(如网站站内搜索、垂直领域知识库搜索等)和核心功能需求(关键词匹配、语义理解、多模态搜索等),根据需求选择技术路线:
- 轻量级方案:若仅需简单文本搜索,可基于开源工具如Elasticsearch或Whoosh构建,Elasticsearch支持分布式存储和高并发,适合中大型数据集;Whoosh则更轻量,适合Python开发者快速集成。
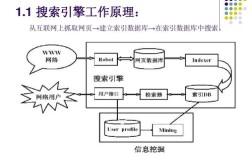
- 自研方案:若需高度定制化(如特定算法或私有化部署),可从底层构建,核心组件包括:索引模块(处理文档分词、建索引)、查询解析模块(分析用户输入)、检索模块(匹配算法)和排序模块(相关性计算)。
数据处理与索引构建
搜索效果的基础是高质量的数据索引,流程分为三步:
- 数据采集:通过API爬取、数据库对接或文件导入(如CSV、JSON)获取原始数据,需注意数据清洗,去除重复项、格式统一化(如日期标准化、HTML标签剥离)。
- 分词处理:将文本拆分为可检索的词汇单元,中文需使用分词器(如Jieba、IKAnalyzer),英文可采用空格与标点分割,同时需构建停用词表(过滤“的”“是”等无意义词)和同义词词典(如“电脑”=“计算机”)。
- 索引创建:将分词后的数据存储为倒排索引(核心数据结构,记录词到文档的映射),文档1包含“苹果 手机”,文档2包含“苹果 公司”,则“苹果”对应的文档列表为[1,2],索引字段需设计权重(如标题权重高于正文),以影响后续排序。
检索与排序实现
用户输入查询词后,系统需完成以下步骤:
- 查询解析:对用户输入进行分词、纠错(如“手ji”修正为“手机”)和扩展(如“电脑”自动关联“笔记本”)。
- 文档匹配:根据倒排索引快速召回包含查询词的文档集合,可通过布尔逻辑(AND/OR)优化匹配范围,如“苹果 手机”需同时包含两个词。
- 相关性排序:结合TF-IDF(词频-逆文档频率)、BM25算法(优化版TF-IDF)或深度学习模型(如BERT)计算文档与查询的相关性分数,同时可引入用户行为数据(如点击率、停留时间)动态调整排序。
前端交互与优化
搜索结果页需提供清晰展示和便捷交互:

(图片来源网络,侵删)
- 结果展示、高亮关键词)和来源URL,支持分页加载。
- 实时搜索:通过前端框架(如React、Vue)实现输入时的联想提示(自动补全),减少用户输入成本。
- 性能优化:采用缓存(如Redis存储热门查询结果)、异步加载和CDN加速,确保响应速度(毫秒级)。
部署与迭代
将搜索服务部署至服务器(如Docker容器化),通过压力测试(如JMeter)验证并发能力,上线后需监控日志(查询词分布、点击率),定期更新索引(如增量更新数据)并迭代算法(如A/B测试排序策略)。
相关问答FAQs
Q1: 开发个人搜索工具需要编程基础吗?
A1: 部分方案无需编程基础,使用WordPress插件(如SearchWP)可快速搭建网站搜索;或借助无代码工具(如Algolia)提供托管服务,仅需配置界面,但若需深度定制(如算法优化),需掌握Python/Java等语言及搜索引擎原理。
Q2: 如何提升搜索结果的准确性?
A2: 可从三方面入手:一是优化分词和同义词库,减少语义偏差;二是引入机器学习模型(如Elasticsearch的Learning-to-Rank),通过用户反馈训练排序算法;三是增加过滤功能(按时间、类别等),帮助用户精准定位目标内容。

(图片来源网络,侵删)