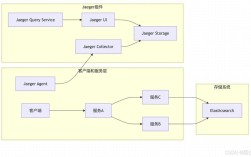
Spark执行命令是大数据处理领域中核心的操作环节,它通过统一的编程接口与集群资源管理器(如YARN、Mesos或Standalone)协作,实现对分布式数据的高效处理,无论是交互式查询、批量数据处理还是机器学习任务,Spark命令的执行都遵循一套严谨的流程,涉及任务提交、资源分配、任务调度与执行等多个环节,以下将从命令提交方式、执行流程、核心参数及优化策略等方面进行详细阐述。

在Spark中,执行命令主要分为两种方式:交互式命令行(如spark-shell)和程序化提交(如spark-submit),交互式命令行适用于快速验证逻辑和探索性分析,用户可在命令行中直接编写Scala或Python代码,Spark会即时解析并执行,在spark-shell中执行sc.textFile("hdfs://path/to/data").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_),可快速完成词频统计任务,而程序化提交则更适合生产环境,用户需将代码打包为JAR文件或Python脚本,通过spark-submit命令提交到集群。spark-submit提供了丰富的参数配置,如--class指定主类、--master指定集群地址、--deploy-mode决定驱动程序部署位置(client或cluster模式)、--executor-memory和--executor-cores设置每个执行器的资源,以及--driver-memory设置驱动程序的内存大小,这些参数直接影响任务的资源分配和执行效率,需根据集群规模和数据量合理配置。
Spark命令的执行流程可分为四个阶段:资源申请、任务划分、任务调度与执行、结果回收,以spark-submit为例,当用户提交命令后,客户端会检查代码和依赖,并向集群管理器(如YARN的ResourceManager)申请资源,集群管理器根据资源分配策略,在集群节点上启动Executor进程,每个Executor拥有独立的内存和CPU核心,并负责执行具体的计算任务,随后,Driver程序将用户代码转换为DAG(有向无环图),DAGScheduler将DAG划分为Stage(阶段),每个Stage由一组可以并行执行的任务(Task)组成,TaskScheduler将Task分配到空闲的Executor上执行,Executor在执行过程中会读取数据(如HDFS、HBase等数据源)、处理数据,并将中间结果存储在内存或磁盘上,Driver汇总各Executor的结果,输出最终结果或写入外部存储系统,整个流程中,Spark通过RDD(弹性分布式数据集)的血缘关系(Lineage)实现容错,当某个Task失败时,可根据血缘关系重新计算该Task,确保任务最终完成。
在执行Spark命令时,参数调优对性能至关重要,以下为常用参数及其影响:
| 参数类别 | 参数名称 | 作用说明 | 推荐配置场景 |
|---|---|---|---|
| 资源分配 | --executor-cores | 每个Executor使用的CPU核心数 | 根据节点CPU核心数和任务并行度设置,通常2-5个核心,避免资源浪费 |
| --executor-memory | 每个Executor的内存大小 | 需考虑数据量、Shuffle内存和缓存需求,一般4-16GB | |
| --driver-memory | Driver程序的内存大小 | 交互式分析或需要大量内存的聚合操作,建议2-8GB | |
| 并行度控制 | --parallelism | RDD操作和Shuffle的并行度 | 通常设置为Executor核心数的2-3倍,或根据数据分区数调整 |
| Shuffle优化 | --spark.shuffle.partitions | Shuffle阶段的分区数 | 数据量大时增加分区数(如200-1000),减少数据倾斜,但需避免过多小任务 |
| 网络与序列化 | --conf spark.serializer | 序列化方式 | 生产环境建议使用Kryo序列化(org.apache.spark.serializer.KryoSerializer) |
| --conf spark.io.compression.codec | 数据压缩方式 | 使用Snappy或LZ4压缩,减少Shuffle数据传输量 | |
| 缓存策略 | .cache() / .persist() | 缓存中间结果到内存或磁盘 | 对重复使用的RDD(如迭代计算)进行缓存,避免重复计算 |
Spark命令的执行还受数据倾斜、资源竞争、GC压力等问题影响,针对数据倾斜,可通过调整分区数、使用Salting技术或倾斜键预处理解决;资源竞争需合理设置Executor数量和核心数,避免单个节点资源过载;GC压力可通过优化堆内存大小(如设置--conf spark.memory.fraction)和使用G1垃圾回收器缓解。

在实际应用中,Spark命令的执行还需结合具体场景优化,在实时流处理(Spark Streaming)中,需合理设置批处理间隔(batchDuration)和检查点(checkpoint)策略;在机器学习(MLlib)中,需调整特征向量的维度和迭代次数以提高模型训练效率,通过监控Spark UI(默认端口4040),可实时查看任务执行进度、资源使用情况和Shuffle数据量,及时发现并解决性能瓶颈。
相关问答FAQs
Q1: 如何解决Spark任务中的数据倾斜问题?
A: 数据倾斜通常表现为少数Task处理的数据量远超其他Task,导致任务执行缓慢,解决方法包括:① 调整Shuffle分区数(如spark.sql.shuffle.partitions),增加并行度;② 对倾斜键进行预处理,如对空值或高频键添加随机前缀(Salting);③ 使用广播变量(Broadcast Variable)将小表数据广播到所有Executor,避免Shuffle;④ 对倾斜键单独处理,如将高频键拆分为多个子键,最后合并结果。
Q2: Spark任务提交时,Cluster模式和Client模式有什么区别?
A: Cluster模式和Client模式主要区别在于Driver程序的部署位置:① Client模式下,Driver运行在提交任务的客户端节点,适用于调试和交互式任务,但客户端节点故障会导致任务失败;② Cluster模式下,Driver运行在集群的Worker节点上,由集群管理器(如YARN)负责容错,更适合生产环境的大规模任务,但调试时日志查看较为复杂,选择模式需根据任务稳定性、调试需求及集群资源管理策略综合决定。