Linux集群命令是管理和维护Linux集群环境的核心工具,涵盖了从节点管理、资源调度到故障排查的多种操作,通过这些命令,管理员可以高效地实现集群的自动化部署、任务分发和状态监控,确保系统的高可用性和性能优化,以下将详细介绍Linux集群中常用的命令及其应用场景,并结合表格形式进行归纳总结。

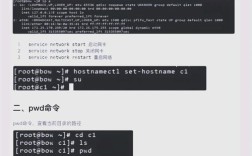
在Linux集群管理中,节点管理是最基础的操作之一,通过SSH(Secure Shell)协议,管理员可以远程登录到集群中的各个节点执行命令,使用ssh user@node-ip命令可以登录到指定节点,而ssh-copy-id user@node-ip则用于将公钥分发到目标节点,实现免密登录,对于批量操作,可以结合for循环和SSH命令,例如for i in {1..5}; do ssh node$i "hostname"; done可以同时查看5个节点的主机名。pdsh是一个并行SSH工具,能够同时在多个节点上执行命令,其基本用法为pdsh -w node1,node2 "uptime",该命令在node1和node2上并行执行uptime命令,极大地提高了管理效率。
集群资源调度是确保任务高效运行的关键,常见的调度工具包括Slurm、PBS和LSF等,以Slurm为例,sinfo命令用于查看集群的整体状态,包括节点状态(如idle、alloc、drain等)和分区信息,通过sinfo -N -l可以获取更详细的节点状态列表。sbatch命令用于提交批处理任务,例如sbatch --job-name=test --output=output.txt ./script.sh会将script.sh作为任务提交,并将输出重定向到output.txt。squeue命令则用于查看任务队列,例如squeue -u username可以显示指定用户的任务状态,对于交互式任务,可以使用srun命令,例如srun --pty bash会在分配的节点上启动一个交互式shell。scancel命令用于取消任务,例如scancel 12345会取消ID为12345的任务。
文件管理在集群中同样重要,尤其是共享文件的访问和同步,NFS(Network File System)是常用的共享文件方案,通过showmount -e server-ip命令可以查看NFS服务器导出的目录列表,而mount server-ip:/share /mnt命令可以将远程共享目录挂载到本地,对于大规模文件分发,rsync是一个高效工具,例如rsync -avz /local/path/ user@node:/remote/path/会将本地目录同步到远程节点,其中-a表示归档模式,-v显示详细过程,-z启用压缩。scp(Secure Copy)用于安全传输文件,例如scp -r local_dir user@node:remote_dir会递归复制本地目录到远程节点。
集群监控与故障排查是保障系统稳定运行的重要环节。top和htop命令可以实时查看节点的CPU和内存使用情况,而mpstat和vmstat则分别用于监控CPU性能和虚拟内存统计,网络方面,ping和traceroute用于测试网络连通性,iftop和nethogs则分别监控网络带宽和进程级别的网络使用情况,对于分布式存储,df -h命令可以查看文件系统的磁盘使用情况,而iostat命令用于监控磁盘I/O性能,日志分析也是故障排查的关键,通过grep和awk工具可以过滤和分析系统日志,例如grep "error" /var/log/syslog | awk '{print $1,$2,$3}'可以提取日志中的错误信息并显示时间戳。

为了更直观地展示常用命令及其功能,以下通过表格进行归纳:
| 命令类别 | 命令示例 | 功能描述 |
|---|---|---|
| 节点管理 | ssh user@node-ip |
远程登录到指定节点 |
pdsh -w node1,node2 "uptime" |
在多个节点上并行执行命令 | |
| 资源调度(Slurm) | sinfo |
查看集群状态和节点分区 |
sbatch script.sh |
提交批处理任务 | |
squeue -u username |
查看指定用户的任务队列 | |
| 文件管理 | mount server-ip:/share /mnt |
挂载NFS共享目录 |
rsync -avz /local/ user@node:/remote/ |
同步本地文件到远程节点 | |
| 监控与排查 | htop |
实时查看CPU和内存使用情况 |
iftop |
监控网络带宽使用情况 | |
grep "error" /var/log/syslog |
过滤系统日志中的错误信息 |
在实际应用中,Linux集群命令的组合使用可以解决复杂问题,当需要检查集群中所有节点的磁盘空间时,可以编写一个脚本结合pdsh和df命令:pdsh -w all "df -h | grep /dev/sda1",该命令会在所有节点上查询/dev/sda1分区的磁盘使用情况,又如,当需要批量更新节点上的软件时,可以使用ansible工具,通过编写Playbook实现自动化部署,例如ansible all -m yum -a "name=nginx state=present"会在所有节点上安装Nginx。
Linux集群命令的熟练掌握需要结合实际场景进行练习,管理员应重点关注命令的参数选项和输出解析,例如sinfo命令的-N参数用于显示节点信息,-l参数用于显示详细信息,集群的安全管理也不容忽视,例如通过iptables或firewalld配置防火墙规则,限制不必要的端口访问,同时定期更新系统和软件包以修复安全漏洞。
相关问答FAQs:

-
问:如何快速检查集群中所有节点的网络连通性?
答: 可以使用pdsh结合ping命令实现,例如pdsh -w all "ping -c 4 8.8.8.8",该命令会在所有节点上ping Google服务器4次,通过输出结果判断网络连通性,如果节点较多,还可以将结果重定向到日志文件,例如pdsh -w all "ping -c 4 8.8.8.8" > network_check.log,便于后续分析。 -
问:在Slurm集群中,如何查看某个任务的详细资源使用情况?
答: 使用sacct命令可以查看任务的资源使用统计,例如sacct -j jobid --format=JobID,JobName,MaxRSS,Elapsed,CPUTime,其中MaxRSS表示任务的最大内存使用量,Elapsed表示任务的实际运行时间,CPUTime表示CPU总时间,如果需要更详细的性能数据,可以结合sstat命令,例如sstat -j jobid --format=MaxRSS,AveCPU。