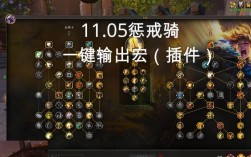
Splunk搜索命令是Splunk平台的核心功能之一,它允许用户通过特定的语法对收集到的数据进行检索、过滤、分析和可视化,这些命令构成了Splunk搜索处理语言(SPL)的基础,结合字段、时间和统计函数,能够帮助用户从海量日志中快速提取有价值的信息,以下将详细介绍Splunk搜索命令的分类、常用命令及其应用场景,并通过表格对比部分命令的语法和功能,最后以FAQs形式解答常见问题。

Splunk搜索命令主要分为三类:搜索命令、生成命令和转换命令,搜索命令用于检索和过滤数据,如search、where、eval;生成命令用于创建新结果或修改现有结果,如stats、chart、timechart;转换命令用于改变结果的格式或结构,如fields、rename、sort,理解这些命令的分类有助于用户根据需求组合使用,构建高效的搜索策略。
在搜索命令中,search是最基础的命令,用于指定搜索条件。error会返回所有包含“error”字段的日志,而source=access_log AND status=500则筛选出来源为access_log且状态码为500的记录。where命令比search更灵活,支持复杂的逻辑表达式,常用于在统计结果中进行二次过滤。stats count by host | where count>100会先按主机统计事件数量,再筛选出计数超过100的主机。
eval命令是数据处理的核心,它允许用户基于现有字段计算新字段或修改字段值。eval latency=response_time-request_time会计算响应时间与请求时间的差值并存储在latency字段中。eval支持多种运算符,如算术运算(、)、字符串函数(upper()、concat())和条件表达式(if、case)。eval status=if(status>=200 AND status<300, "success", "failure")会根据HTTP状态码定义状态字段。
生成命令中,stats是最常用的统计命令,用于聚合数据,它可以计算计数(count)、求和(sum)、平均值(avg)等,并支持按字段分组。stats avg(latency) by host会按主机分组计算平均延迟。chart和timechart则用于可视化统计结果,其中timechart专门用于时间序列数据。timechart count(status=500) span=1h会每小时统计500错误的发生次数,并生成时间折线图。

转换命令用于调整结果的显示方式。fields命令用于选择或排除字段,如fields host, latency只显示host和latency字段。rename用于重命名字段,例如rename old_field AS new_field。sort命令用于排序结果,默认按升序排列,sort -count可按降序排列。dedup命令用于去重,head和tail用于限制结果数量,例如head 10只返回前10条记录。
以下表格对比了部分常用Splunk搜索命令的语法和功能:
| 命令 | 语法示例 | 功能描述 |
|---|---|---|
| search | search error OR warning |
检索包含“error”或“warning”的记录 |
| eval | eval new_field=old_field*2 |
计算新字段值,支持算术、字符串和逻辑运算 |
| stats | stats count by host |
按host字段分组统计记录数量 |
| timechart | timechart count span=5m |
按时间间隔(5分钟)统计事件数量并生成时间序列图 |
| fields | fields -password |
排除password字段,仅显示其他字段 |
| sort | sort -latency |
按latency字段降序排列结果 |
| where | where latency>1000 |
筛选满足条件的记录,常与stats结合使用 |
| dedup | dedup host |
按host字段去重,保留每个host的第一条记录 |
| rex | rex "user=(?<username>\w+)" |
使用正则表达式提取字段,将匹配内容存储到username字段 |
在实际应用中,命令的组合使用能实现复杂分析,分析Web服务器错误日志时,可通过source=access_log AND status=500 | eval error_code=substr(status,1,3) | stats count by error_code | sort -count统计不同错误码的出现次数并排序,若需进一步分析错误时间分布,可添加timechart count(error_code) span=1h生成时间趋势图。
Splunk搜索命令的强大之处在于其灵活性和可扩展性,用户可以通过管道()连接多个命令,逐步处理数据。index=web sourcetype=access_log | eval load_time=resp_time-req_time | stats avg(load_time) by page | where avg(load_time)>2 | sort -avg(load_time)先计算页面加载时间,再统计平均值并筛选出加载时间超过2秒的页面,最后按加载时间降序排列。

需要注意的是,搜索命令的性能优化至关重要,在处理大数据集时,应尽量使用早期过滤命令(如search、where)减少数据量,避免在数据量较大时使用高资源消耗的命令(如stats without by),合理使用时间范围(如earliest=-1h)和索引过滤(如index=main)能显著提升搜索速度。
相关问答FAQs:
-
问:如何使用Splunk命令提取日志中的特定字段?
答:可以使用rex命令结合正则表达式提取字段,若日志格式为“2023-10-01 10:00:00 INFO user=admin action=login”,可通过rex "user=(?<user>\w+)"提取user字段,提取后的字段可在后续命令中使用,若字段格式固定,也可在Splunk的props.conf中配置字段提取规则,实现自动解析。 -
问:Splunk搜索中
stats和eventstats命令有什么区别?
答:stats命令会聚合数据并生成新的统计结果,覆盖原始事件数据;而eventstats命令在保留原始事件的同时,添加统计字段。stats count by host会返回每个主机的事件计数,而eventstats count by host会在每条事件中添加count字段,显示该主机的事件总数,适用于需要在原始数据中添加统计信息的场景。