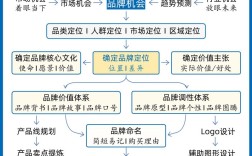
sort命令与index命令区别详解:从原理到实战,一文搞懂数据排序与索引
** 在数据处理与分析领域,sort命令和index命令是两个核心概念,许多初学者甚至部分开发者常常混淆二者,本文将从定义、核心功能、应用场景、工作原理等多个维度,深入浅出地剖析sort命令与index命令的本质区别,并结合实例演示,助您彻底掌握这两个命令,提升数据处理效率。

引言:为什么必须区分sort和index?
当我们面对海量数据时,如何快速找到需要的信息?如何让数据变得有序以便分析?sort和index这两个命令,正是解决这两个问题的利器,它们扮演的角色截然不同。
sort命令关注的是“顺序”:它将数据重新排列,使其按照某种规则(如字母、数字、时间)变得井井有条。index命令关注的是“位置”:它像一本书的目录,为数据建立快速查找的标记,但不改变数据的原始物理顺序。
混淆这两者,可能导致数据处理效率低下、逻辑错误,甚至得出错误的结论,我们将进行全方位的对比。
核心定义与核心功能:它们到底是什么?
sort命令:数据的“整理师”
sort命令,顾名思义,其核心功能是排序,它接收一组无序或部分有序的数据,并根据用户指定的键和排序规则(升序、降序、自定义等),对数据进行重新排列,生成一个全新的、有序的数据集。
- 核心目标:改变数据的物理顺序,使其有序化。
- 好比什么:就像整理一堆散乱的扑克牌,你按照花色和大小将它们一张张排列好,形成一摞整齐的牌。
index命令:数据的“导航图”
index命令,在数据库和搜索引擎领域更为常见,其核心功能是建立索引,它通过分析数据中的特定列(或字段),创建一个指向数据原始位置的、高效的数据结构(如B+树、哈希表等),这个数据结构就是索引。

- 核心目标:不改变数据本身,而是创建一个“快速查找目录”,极大提升数据检索速度。
- 好比什么:就像一本书的目录,目录本身并不包含书的全部内容,但它告诉你“XX’的内容在第XX页”,当你想查找特定内容时,无需翻遍全书,只需查目录即可直达目标页。
多维深度对比:从五个方面看本质差异
为了更清晰地理解,我们从五个关键维度对sort和index进行对比。
| 对比维度 | sort命令 (排序) | index命令 (索引) |
|---|---|---|
| 核心目的 | 改变数据顺序,使其有序。 | 加速数据检索,建立快速查找路径。 |
| 数据顺序 | 改变数据的物理存储顺序,生成一个全新的有序结果。 | 不改变数据的物理存储顺序,数据仍在原位,只是多了个“路标”。 |
| 主要操作 | 比较和交换,对数据进行多次比较,然后交换位置以形成有序序列。 | 创建和维护,在特定列上构建一个专门的数据结构(如B+树)。 |
| 性能影响 | 写入时慢,读取时快(针对有序数据),排序是一个计算密集型操作,尤其是大数据集,耗时较长,但一旦有序,顺序遍历会很快。 | 写入时慢,读取时极快,创建和维护索引需要额外的时间和空间成本,但一旦建立,数据查询(特别是WHERE、JOIN操作)速度会指数级提升。 |
| 典型应用场景 | 数据预处理,为分析做准备。 生成有序报告(如按销售额排名)。 去重(配合 uniq命令)。合并多个有序文件。 |
数据库表的快速查询(如WHERE id = 123)。加速表连接操作。 防止全表扫描,提升系统响应速度。 |
实战演示:用代码说话,感受差异
假设我们有一个名为 users.csv 的用户数据文件,内容如下:
user_id,username,signup_date,last_login 105,Charlie,2025-01-15,2025-10-20 101,Alice,2025-05-20,2025-10-18 103,Bob,2025-03-10,2025-10-21 102,David,2025-11-01,2025-10-19
使用 sort 命令
目标:希望用户按 signup_date(注册日期)的升序排列,看看谁是最早注册的用户。
操作 (Linux Shell):

sort -t ',' -k 3 users.csv
命令解释:
-t ',': 指定逗号 为字段分隔符。-k 3: 指定按第3个字段 (signup_date) 进行排序。
输出结果:
101,Alice,2025-05-20,2025-10-18 102,David,2025-11-01,2025-10-19 103,Bob,2025-03-10,2025-10-21 105,Charlie,2025-01-15,2025-10-20
分析:观察输出,你会发现数据的行顺序完全改变了,Alice的记录从第二行变成了第一行。sort命令为我们生成了一个全新的、按注册日期排序的文件,这就是改变物理顺序。
使用 index 命令 (以数据库为例)
目标:希望根据 user_id 快速查找到某个用户的信息,而不是每次都从头到尾扫描整个文件。
操作 (SQL - 以MySQL为例):
-- 在 user_id 列上创建索引 CREATE INDEX idx_user_id ON users(user_id); -- 现在使用 WHERE 条件查询 SELECT * FROM users WHERE user_id = 103;
过程分析:
- 创建索引:
CREATE INDEX命令会扫描users表,为user_id这一列的每一个值建立一个B+树索引结构,这个过程需要时间,并且会占用额外的磁盘空间。 - 执行查询: 当执行
SELECT * FROM users WHERE user_id = 103;时,数据库不会去扫描表中的4行数据,它会直接跳到idx_user_id索引,快速定位到user_id=103所在的“位置”,然后根据这个位置信息,直接从数据文件中提取出Bob的完整记录。
分析:在查询完成后,users 表中数据的行顺序仍然是原始的顺序:
105,Charlie,2025-01-15,2025-10-20 101,Alice,2025-05-20,2025-10-18 103,Bob,2025-03-10,2025-10-21 102,David,2025-11-01,2025-10-19
index没有改变数据,只是为数据建立了一个“高速公路入口”,让查询变得飞快,这就是不改变物理顺序,加速检索。
何时使用,何时不使用?
通过以上对比,我们可以得出清晰的结论:
-
你应该使用
sort当:- 你的核心需求是让数据变得有序,以便于阅读、展示或进行后续的顺序处理(如合并、分组)。
- 你需要生成一份排行榜、一份时间序列报告。
- 你在进行数据清洗和预处理,将杂乱的数据整理成标准格式。
-
你应该使用
index当:- 你的核心需求是快速查找特定条件的数据。
- 你在一个大型数据库中,频繁地使用
WHERE、JOIN、ORDER BY等子句。 - 系统的查询性能至关重要,你需要避免耗时的全表扫描。
重要提示:sort和index并非相互排斥,它们可以协同工作,你可以在一个已建立索引的列上进行排序,数据库会利用索引来加速排序操作,因为索引本身就已经是有序的。
延伸思考:高级应用与性能考量
- 多列排序与复合索引:
sort可以指定多个键进行多级排序,同样,index也可以创建包含多个列的复合索引,以应对更复杂的查询场景。 - 索引的代价:索引不是免费的,它会增加写入(INSERT, UPDATE, DELETE)的开销,因为每次数据变动都需要同步更新索引结构,它也会占用额外的存储空间,只为经常用于查询条件的列创建索引。
- 不同工具中的实现:虽然原理相通,但在不同的工具(如Linux Shell、数据库、编程语言库、Elasticsearch)中,
sort和index的具体语法和实现细节有所不同,但其核心逻辑始终如一。
掌握sort命令与index命令的区别,是每一位数据从业者、开发者和系统管理员的必备技能,前者是“整理的艺术”,后者是“速度的魔法”,理解了“改变顺序”与“加速查找”这一根本区别,您就能在处理数据时游刃有余,构建出更高效、更强大的应用。
希望本文能为您拨开迷雾,真正搞懂这两个强大命令的本质,如果您有任何疑问或想分享您的实战经验,欢迎在评论区留言讨论!
SEO关键词标签: sort命令, index命令, sort与index区别, 数据排序, 数据库索引, 数据查询优化, Linux sort, 数据库性能, 大数据处理