Hive作为基于Hadoop的数据仓库工具,提供了类SQL的查询语言HiveQL,用户可以通过命令行界面(CLI)或Hue等工具执行基本操作,以下从数据库管理、表操作、数据查询与加载、分区管理四个方面详细介绍Hive基本命令。

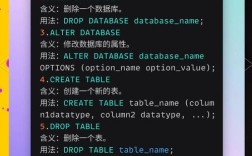
数据库管理是Hive操作的基础,创建数据库使用CREATE DATABASE [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path],其中IF NOT EXISTS可避免重复创建错误,LOCATION指定数据库在HDFS上的存储路径。CREATE DATABASE user_db COMMENT '用户信息数据库' LOCATION '/user/hive/warehouse/user_db.db',切换数据库需执行USE database_name,后续命令将在此数据库下执行,查看所有数据库可用SHOW DATABASES,过滤数据库则用SHOW DATABASES LIKE 'db_name*',删除数据库时,若包含表需先删除表或使用DROP DATABASE [IF EXISTS] database_name [CASCADE],CASCADE会级联删除数据库内的所有表。
表操作是数据管理的核心,创建表分为内部表和外部表,内部表语法为CREATE TABLE [IF NOT EXISTS] table_name (col_name data_type [COMMENT col_comment], ...) [COMMENT table_comment] [ROW FORMAT row_format] [STORED AS file_format],例如CREATE TABLE users (id INT, name STRING, age INT) COMMENT '用户表' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE,外部表需添加EXTERNAL关键字,并通过LOCATION指定数据路径,删除外部表时仅删除元数据,HDFS数据保留,修改表结构可使用ALTER TABLE table_name ADD|REPLACE|DROP COLUMNS (col_name data_type, ...),如添加列ALTER TABLE users ADD COLUMN (email STRING),加载数据到表有两种方式:LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE table_name,LOCAL表示从本地文件系统加载,否则从HDFS加载;OVERWRITE会覆盖表中已有数据,还可通过INSERT INTO TABLE table_name SELECT ...从查询结果加载数据。
数据查询与操作依赖HiveQL语法,基本查询与SQL类似,SELECT [ALL | DISTINCT] select_expr, ... FROM table_name [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [ORDER BY col_list [ASC | DESC]] [LIMIT number],聚合函数如COUNT(), SUM(), AVG()等可直接使用,例如SELECT department, AVG(salary) FROM employees GROUP BY department,多表连接查询支持JOIN(内连接)、LEFT JOIN(左连接)、RIGHT JOIN(右连接)等,如SELECT a.id, b.name FROM orders a JOIN customers b ON a.cust_id = b.id,CTE(公用表表达式)可通过WITH clause_name AS (SELECT ...) SELECT ...简化复杂查询。
分区管理可提升查询效率,创建分区表需在CREATE TABLE语句中指定PARTITIONED BY (partition_col data_type, ...),例如CREATE TABLE sales (id INT, amount DOUBLE) PARTITIONED BY (date STRING, region STRING),添加分区使用ALTER TABLE table_name ADD PARTITION (partition_col1='value1', partition_col2='value2') [LOCATION 'hdfs_path'],删除分区则用ALTER TABLE table_name DROP PARTITION (partition_col1='value1', ...),查看分区信息可通过SHOW PARTITIONS table_name,或查询PARTITIONS表(如SELECT * FROM sales PARTITIONS(date='2023-01-01')),动态分区可简化分区创建,需设置hive.exec.dynamic.partition=true和hive.exec.dynamic.partition.mode=nonstrict,然后在INSERT语句中指定静态分区列,动态分区列通过SELECT语句输出。

相关问答FAQs
Q1: Hive内部表与外部表的区别是什么?如何选择?
A1: 内部表由Hive完全管理,删除表时会同时删除HDFS上的数据文件;外部表仅记录元数据,删除表时HDFS数据保留,适合存储原始数据或需被其他工具共享的场景,选择时,若数据需长期存储或需跨工具访问,使用外部表;若数据仅用于Hive分析且需自动清理,使用内部表。
Q2: Hive分区和分桶的作用是什么?如何提升查询性能?
A2: 分区通过将表数据按列值拆分为子目录,减少扫描数据量(如按日期分区后查询某日数据只需扫描对应目录);分桶则通过哈希函数将数据拆分为固定数量的文件,适合高效采样和join操作(如两表分桶键相同可mapjoin),两者结合可显著提升查询性能,尤其适用于大数据量场景。