在Linux系统中,处理重名文件是日常运维和开发中常见的需求,无论是批量重命名、查找重复文件,还是避免文件名冲突,都需要借助特定的命令工具,以下将详细介绍Linux中处理重名文件的核心命令及其使用方法,包括mv、rename、find、fdupes等工具的实践技巧和注意事项。

基础重命名命令:mv
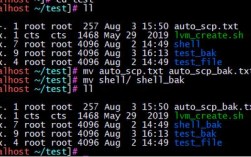
mv(move)是Linux中最基础的文件移动/重命名命令,适用于单个文件或少量文件的重命名操作,其基本语法为mv [选项] 源文件 目标文件,当目标文件与现有文件重名时,mv默认会覆盖目标文件,因此需谨慎使用。
示例1:简单重命名
将file1.txt重命名为file2.txt:
mv file1.txt file2.txt
示例2:避免覆盖
使用-i选项(interactive模式)可在覆盖前提示确认:
mv -i file1.txt file2.txt # 若file2.txt存在,会提示是否覆盖
示例3:批量重命名(结合循环)
若需将当前目录下所有.txt文件中的old替换为new,可通过for循环实现:

for file in *.txt; do
mv "$file" "${file/old/new}"
done
注意:循环中需用双引号包裹文件名,避免因文件名含空格或特殊字符导致错误。
高级批量重命名:rename
rename命令支持基于Perl正则表达式的批量重命名,功能更强大,适合复杂场景,系统可能安装有prename(Perl版)或rename(util-linux版),需通过man rename确认版本。
语法:rename '表达式@' 文件列表
示例1:数字序号重命名
将file1.txt、file2.txt...重命名为doc_1.txt、doc_2.txt...:

rename 's/^file/doc_' -e 's/\.txt$/_&/' *.txt
解析:s/^file/doc_将文件名开头的file替换为doc_;s/\.txt$/_&/在.txt前添加下划线,&表示匹配的原内容。
示例2:删除文件名中的特定字符
删除所有.jpg文件名中的tmp_:
rename 's/tmp_//' *.jpg
示例3:大小写转换
将所有文件名转为小写:
rename 'tr/A-Z/a-z/' *
查找与处理重复文件:find与fdupes
使用find查找重复文件
find命令可根据文件大小、哈希值等条件查找重复文件,以下是通过文件大小初步筛选,再用md5sum校验的示例:
步骤1:按大小分组查找
查找当前目录下大小超过1MB的文件并按大小分组:
find . -type f -size +1M -exec ls -lh {} + | awk '{print $5, $9}' | sort -nr | uniq -d
解析:-size +1M筛选大于1MB的文件;ls -lh显示大小和路径;awk提取大小和文件名;sort -nr按数字降序排序;uniq -d输出重复行。
步骤2:计算哈希值确认重复
对大小相同的文件计算MD5值:
find . -type f -size +1M -exec md5sum {} + | sort | uniq -D -w 32
解析:md5sum生成文件哈希值;sort排序后,uniq -D -w 32输出哈希值重复的行(-w 32指定比较前32个字符,即MD5值)。
使用fdupes工具
fdupes是专门查找重复文件的工具,安装后可直接使用:
sudo apt install fdupes # Debian/Ubuntu系统
示例1:递归查找重复文件
fdupes -r /path/to/directory
示例2:删除重复文件(保留最新)
结合find和xargs删除重复文件(需谨慎操作):
fdupes -r --delete /path/to/directory
注意:--delete会交互式提示删除,建议先使用-N选项预览。
避免文件名冲突的实践技巧
- 使用唯一前缀/后缀:在批量操作前,为文件名添加时间戳或随机字符串,如
mv file.txt "$(date +%Y%m%d)_file.txt"。 - 临时文件处理:使用
mktemp创建临时文件,避免与现有文件冲突:temp_file=$(mktemp) cp source.txt "$temp_file"
- 脚本安全模式:在重命名脚本中添加
set -e,遇错立即退出,避免连锁覆盖。
命令对比与适用场景
| 命令 | 功能特点 | 适用场景 | 示例 |
|---|---|---|---|
mv |
基础重命名,需手动处理冲突 | 单个或少量文件重命名 | mv old.txt new.txt |
rename |
Perl正则批量重命名 | 复杂模式匹配的批量重命名 | rename 's/\.bak$//' *.bak |
find |
灵活查找+哈希校验重复文件 | 需自定义条件查找重复文件 | find . -type f -exec md5sum {} + |
fdupes |
专用重复文件查找与删除 | 大规模目录重复文件管理 | fdupes -r --delete /dir |
相关问答FAQs
Q1: 如何批量将文件名中的空格替换为下划线?
A1: 可使用rename命令结合Perl正则表达式实现:
rename 's/\s/_/g' *
解析:\s匹配空格,g表示全局替换,表示当前目录所有文件,若需递归处理子目录,可结合find:
find . -type f -exec rename 's/\s/_/g' {} +
Q2: 删除重复文件时如何确保保留最新修改的文件?
A2: 可通过find按修改时间排序后,删除旧文件,删除目录下重复的.log文件,保留最新的:
find . -type f -name "*.log" -exec md5sum {} + | sort | uniq -D -w 32 | awk '{print $2}' | sort | uniq -f 1 | xargs rm -f
解析:
md5sum生成哈希值和文件路径;sort和uniq -D输出重复文件行;awk提取文件路径并按修改时间排序(需结合stat命令调整);uniq -f 1跳过每组第一个文件(最新文件),xargs rm -f删除剩余文件。
注意:实际操作前建议先用ls -lt验证文件顺序,避免误删。