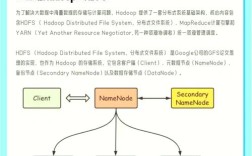
在Hadoop分布式文件系统(HDFS)中,解压缩命令主要用于处理存储在HDFS上的压缩文件,以释放存储空间或提取原始数据用于后续处理,Hadoop支持多种压缩格式,如gzip、bzip2、LZO、Snappy等,不同的压缩格式需要使用对应的解压缩工具或命令,以下是HDFS中常用的解压缩命令及操作方法。

(图片来源网络,侵删)
基本解压缩命令
-
使用hadoop fs -get命令本地解压缩
该命令可将HDFS上的压缩文件下载到本地文件系统,并利用本地工具解压,解压gzip文件:hadoop fs -get /path/to/compressed/file.gz . # 下载到当前目录 gunzip file.gz # 本地解压
此方法适用于小文件,但大文件下载可能耗时较长。
-
使用hadoop fs -cat命令结合管道解压
通过hadoop fs -cat读取压缩文件内容,并通过管道传递给本地解压工具。hadoop fs -cat /path/to/file.gz | gunzip > output.txt
此方法无需下载整个文件,适合流式处理,但需确保本地已安装对应解压工具。
 (图片来源网络,侵删)
(图片来源网络,侵删) -
使用hadoop jar命令运行解压缩程序
对于Hadoop原生支持的压缩格式(如gzip、bzip2),可通过hadoop jar调用Hadoop内置的解压缩类。hadoop jar hadoop-streaming.jar -input /path/to/input.gz -output /path/to/output
此方法适用于MapReduce任务中的解压操作,需配合Streaming API使用。
不同压缩格式的解压方法
以下是常见压缩格式在HDFS中的解压操作对比:
| 压缩格式 | 扩展名 | HDFS解压命令示例 | 适用场景 |
|---|---|---|---|
| Gzip | .gz | hadoop fs -cat file.gz | gunzip > output |
通用文本压缩,兼容性好 |
| Bzip2 | .bz2 | hadoop fs -cat file.bz2 | bunzip2 > output |
高压缩率,但速度较慢 |
| LZO | .lzo | hadoop fs -cat file.lzo | lzop -d |
需安装LZO库,适合大数据快速解压 |
| Snappy | .snappy | hadoop fs -cat file.snappy | snappy decompress |
高速压缩,适合实时处理 |
注意事项
- 权限问题:确保执行解压操作的用户对HDFS文件有读取权限。
- 磁盘空间:解压后文件体积可能显著增大,需检查目标目录的剩余空间。
- 格式兼容性:部分压缩格式(如LZO)需提前安装Hadoop的本地库支持。
- 性能优化:大文件解压建议使用分布式计算框架(如MapReduce)而非本地工具,以提高效率。
相关问答FAQs
Q1: 如何在Hadoop集群中批量解压多个.gz文件?
A1: 可以通过循环结合hadoop fs -cat和gunzip实现批量解压。

(图片来源网络,侵删)
for file in $(hadoop fs -ls /input_dir/*.gz | awk '{print $8}'); do
hadoop fs -cat $file | gunzip > ./output/$(basename $file .gz)
done
若需分布式处理,可编写MapReduce程序,将解压逻辑作为Mapper阶段的输入处理。
Q2: 解压后的文件如何直接存储回HDFS?
A2: 使用管道将解压后的数据流直接写入HDFS,避免本地存储。
hadoop fs -cat /input/file.gz | gunzip | hadoop fs -put - /output/file.txt
此方法适合大文件解压,但需确保网络带宽充足,以避免性能瓶颈。