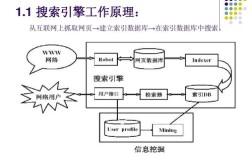
网站制作搜索引擎是一个涉及技术选型、架构设计、数据处理和用户交互的系统工程,通常需要结合爬虫、索引、检索和排序等多个模块来实现,以下从核心步骤、技术细节和优化方向展开详细说明。

明确需求与技术选型
在开始制作搜索引擎前,需先明确目标:是站内搜索(如电商网站商品搜索)还是全网搜索(如百度、谷歌)?前者聚焦结构化数据,后者需处理海量非结构化数据,技术选型上,小型项目可基于开源工具快速搭建,大型项目则需分布式架构支持,站内搜索可使用Elasticsearch或Solr,而全网搜索需自研爬虫或结合Nutch等框架。
数据采集:爬虫系统设计
爬虫是搜索引擎的“数据源”,负责从互联网或目标网站抓取网页内容,需解决三个核心问题:
- 抓取策略:采用广度优先(BFS)或深度优先(DFS)遍历网页,通过队列管理URL,避免重复抓取(使用布隆过滤器去重)。
- 反爬机制:设置User-Agent代理、IP轮换(代理池)、请求频率控制(如随机延迟),遵守robots.txt协议。
- 数据解析:使用BeautifulSoup(Python)或Jsoup(Java)提取HTML中的文本、标题、链接等结构化数据,存储为原始文档(如JSON或HTML文件)。
爬虫架构示例:
| 模块 | 功能描述 | 常用工具 |
|---------------|-----------------------------------|------------------------|
| URL管理器 | 存储待抓取URL和已抓取URL | Redis、MySQL |
| 网页下载器 | 发送HTTP请求获取网页内容 | Scrapy、Selenium |
| 网页解析器 | 提取文本和链接 | BeautifulSoup、PyQuery |
| 数据存储器 | 保存原始数据或清洗后数据 | MongoDB、HBase |
数据预处理:清洗与分词
原始数据需经过清洗和结构化处理,才能用于索引。

- 数据清洗:去除HTML标签、JavaScript代码、广告等噪声,提取正文内容;对文本进行标准化(如统一大小写、去除停用词“的”“是”等)。
- 分词处理:中文需分词(如“搜索引擎”切分为“搜索”“引擎”),常用工具包括Jieba、IK Analyzer;英文按空格和标点分词。
- 特征提取:通过TF-IDF(词频-逆文档频率)或Word2Vec将文本转换为向量,用于后续排序。
索引构建:倒排索引设计
索引是搜索引擎的核心,直接影响检索效率,倒排索引是最常用的结构,记录每个词对应的文档列表及位置信息。
- 索引结构:
- 词典:存储所有分词,每个词对应一个倒排列表(如“搜索→[doc1:3次, doc5:1次]”)。
- 倒排列表:包含文档ID、词频(TF)、词位置等信息,支持快速检索。
- 索引生成流程:
- 将清洗后的文档分词后,遍历每个词,更新倒排列表;
- 定期合并索引段(如Lucene的合并策略),优化查询性能。
- 工具选择:Elasticsearch基于Lucene实现,自动管理倒排索引;Solr适合需要复杂查询的场景(如全文检索、聚合分析)。
检索与排序:相关性算法
用户输入查询词后,系统需快速返回相关结果,排序算法是关键。
- 检索流程:
- 对查询词分词,在倒排索引中查找对应的文档列表;
- 合并多个词的文档列表(如AND/OR逻辑),通过布尔模型筛选候选文档。
- 排序算法:
- 传统方法:TF-IDF(词频越高、文档越稀有则排名越靠前)、BM25(优化TF-IDF的饱和函数)。
- 机器学习:训练排序模型(如LambdaMART、深度学习模型),结合用户点击率、停留时间等行为数据优化排序。
- 性能优化:使用缓存(如Redis存储热门查询结果)、并行计算(MapReduce处理大规模索引)。
用户交互与结果展示
检索结果需以友好方式呈现,提升用户体验。
- 分页与高亮:支持分页加载(每页10-20条),对查询词在结果中高亮显示(如用
<em>标签包裹)。 - 查询扩展:通过同义词库(如“电脑”→“计算机”)或纠错(如“ serch ”→“search”)提升召回率。
- 界面设计:简洁的搜索框、筛选功能(按时间、类别排序)、搜索建议(输入时提示热门词)。
维护与迭代
搜索引擎需持续优化:

- 监控与日志:记录查询日志(用户输入、点击结果),分析低频查询或无结果查询,优化索引覆盖;
- 索引更新:定时增量更新索引(如每小时抓取新数据),或实时更新(如Kafka+Elasticsearch流式处理);
- A/B测试:对比不同排序算法或界面设计的点击率,迭代优化策略。
相关问答FAQs
Q1: 站内搜索和全网搜索的技术选型有何区别?
A1: 站内搜索数据量小、结构化程度高,推荐使用Elasticsearch或Solr,它们内置分词、聚合等功能,开发效率高;全网搜索需处理海量数据和高并发,需自研分布式爬虫(如Scrapy+分布式队列)、结合Hadoop/HDFS存储原始数据,使用Spark进行批量索引更新,排序模型需更复杂(如深度学习排序)。
Q2: 如何提升搜索引擎的召回率和准确率?
A2: 召回率(返回相关结果的比例)可通过扩展同义词库、使用模糊匹配(如拼音搜索)、增加索引覆盖范围来提升;准确率(结果的相关性)则需优化排序算法(如结合BM25和机器学习模型)、过滤低质量内容(如去重、垃圾广告识别),并利用用户反馈(如点击数据)训练排序模型,持续迭代优化。