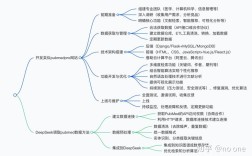
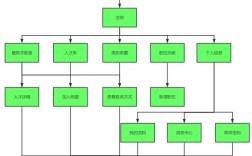
搭建搜索平台是一个系统性工程,涉及需求分析、技术选型、数据采集、索引构建、服务开发、测试优化等多个环节,每个环节的紧密配合是平台高效稳定运行的关键,以下从流程角度详细拆解各阶段的核心工作与实施要点。

需求分析与规划
在项目启动初期,需明确搜索平台的核心目标与业务场景,首先要梳理用户需求,例如是企业内部文档检索、电商商品搜索还是内容平台的全站搜索,不同场景对搜索结果的排序相关性、实时性、个性化等要求差异显著,其次需分析数据特性,包括数据类型(文本、数值、图片等)、数据量级(千万级还是百亿级)、更新频率(实时或批量)等,这些将直接影响后续技术架构的选择,同时需定义核心指标,如搜索响应时间(要求毫秒级)、召回准确率(Top5结果的相关性占比)、用户点击率等,为后续优化提供量化依据,此阶段还需输出详细的需求文档,明确功能边界与非功能需求,如高并发支持(峰值QPS)、容灾能力等。
技术选型与架构设计
根据需求分析结果,进行技术栈与架构的选型,数据采集层,若数据源为数据库,可采用CDC(变更数据捕获)工具如Canal、Debezium实现实时同步;若为网页或API数据,可使用爬虫框架(Scrapy)或日志采集工具(Fluentd、Logstash),数据存储层,需区分原始数据存储(如HDFS、MinIO)与索引存储,搜索引擎核心可选择Elasticsearch、Apache Solr或自研倒排索引引擎,其中Elasticsearch因分布式架构与生态完善成为主流选择,服务层需设计API网关统一处理请求,实现查询解析、路由转发、结果聚合等功能,同时引入缓存(Redis)减轻后端压力,架构设计需考虑高可用,采用多节点集群部署,负载均衡(Nginx、HAProxy)分发流量,并制定数据备份与故障切换机制。
数据采集与预处理
数据采集是搜索平台的数据基础,需对接各类数据源并建立标准化流程,对于结构化数据(如MySQL表),通过Canal监听binlog日志,将增量数据实时写入消息队列(Kafka),再由消费者程序处理;对于非结构化数据(如PDF、Word文档),需通过OCR或文档解析库(Tika)提取文本内容,并统一转换为JSON格式,预处理环节包括数据清洗(去除HTML标签、特殊字符)、数据校验(检查字段完整性)、数据转换(分词、标准化,如日期格式统一)等,其中分词是关键步骤,需根据语言特性选择分词器(如中文的IK Analyzer、Jieba),并自定义词典(如专业术语、品牌名)提升分词准确性,处理后的数据暂存于Kafka或直接写入原始数据存储,等待索引构建。
索引构建与优化
索引是提升搜索效率的核心,需根据数据特性选择合适的索引结构与构建策略,倒排索引是最常用的索引结构,通过“词-文档ID”映射实现快速召回,Elasticsearch默认使用Lucene的倒排索引,索引构建可分为全量构建与增量构建:全量构建适用于历史数据初始化,可通过批量导入API(Elasticsearch的Bulk API)实现;增量构建则通过实时或准实时同步机制,将预处理后的数据写入索引,确保数据新鲜度,索引优化方面,需合理设计字段类型(如text用于全文检索、keyword用于精确匹配)、配置分词器(如ik_max_word细粒度分词)、设置索引生命周期管理(ILM)自动清理过期数据,对于大规模数据,可采用分片(Sharding)策略,将索引拆分为多个分片存储在不同节点,提升并行处理能力,同时通过副本(Replica)保证数据可用性。

搜索服务开发与功能实现
搜索服务层是用户直接交互的接口,需实现查询解析、结果排序、个性化推荐等功能,查询解析阶段,需将用户输入的自然语言语句转换为结构化查询语句,支持关键词匹配、模糊查询(如通配符“*”)、范围查询(如价格区间)等高级语法,同时通过查询改写(如同义词扩展、纠错)提升召回率,结果排序是核心环节,需结合相关性算法(如BM25、TF-IDF)、业务规则(如商品销量、权重)以及用户画像(如历史点击偏好)进行多维度排序,Elasticsearch可通过Function Score Query实现复杂排序逻辑,功能扩展上,可添加搜索联想(基于用户输入实时推荐候选词)、搜索结果高亮(关键词标记)、筛选与聚合(如按品牌、分类筛选)等交互功能,并通过API网关暴露给前端应用。
测试、上线与运维
上线前需进行全面测试,包括功能测试(验证查询准确性、排序逻辑)、性能测试(模拟高并发场景,测试响应时间与吞吐量)、压力测试(极限QPS下的稳定性)等,确保平台满足需求指标,上线阶段可采用灰度发布,逐步将流量切换至新集群,监控关键指标(如错误率、响应延迟)及时回滚,运维阶段需建立监控体系,通过Prometheus+Grafana监控集群资源(CPU、内存、磁盘I/O)、索引状态、查询延迟等,设置告警规则(如节点离线、CPU使用率超80%)及时处理故障,同时需定期优化索引(如段合并、冷热数据分离)、升级版本(修补安全漏洞)、扩容缩容(根据数据量调整节点数量),保障平台长期稳定运行。
相关问答FAQs
Q1:搜索平台如何平衡召回率与准确率?
A:召回率指相关结果被检出的比例,准确率指检出的结果中相关结果的比例,两者通常存在trade-off,可通过调整查询逻辑优化,如扩大查询范围(使用“OR”连接同义词)提升召回率,增加过滤条件(如时间、地域)或优化排序算法(如提升权重)提升准确率;同时引入机器学习模型(如Learning to Rank)对结果进行重排序,在保证召回的基础上精准排序,实现动态平衡。
Q2:面对海量数据,如何提升搜索平台的实时性?
A:实时性优化需从数据同步与索引构建两方面入手,数据同步采用流式处理架构,如Kafka+Flink,将数据延迟控制在秒级;索引构建采用“索引+缓存”模式,新数据先写入内存缓冲区(Elasticsearch的Translog),实时可见,再异步刷磁盘,同时通过refresh_interval参数控制内存数据刷新到磁盘的频率(如默认1秒),平衡实时性与I/O压力;对于超大规模场景,可采用独立的实时索引与离线索引,通过路由策略将查询分流至实时索引优先处理。