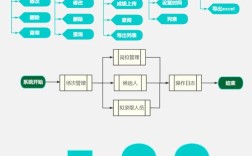
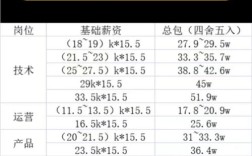
下面我将为您全面、系统地梳理阿里巴巴数据岗位的招聘要求,涵盖通用能力、不同岗位的硬技能、软技能以及招聘流程,并附上一些针对性的建议。
通用能力与素质 (所有数据岗位的基石)
无论您是应聘数据分析师、数据工程师还是数据科学家,以下这些通用能力都是阿里巴巴非常看重的:
-
技术基本功扎实:
- 编程能力:熟练掌握至少一门主流编程语言(Python 是首选,其次是 Java/Scala)。
- 数据结构与算法:具备扎实的数据结构和算法基础,这是技术面试的必考项。
- 计算机基础:对操作系统、计算机网络、数据库原理有深入理解。
-
数据敏感性与逻辑思维:
- 能够从海量、杂乱的数据中发现问题、定位问题、找到规律。
- 具备严谨的逻辑推理能力,能够构建清晰的因果链条。
-
业务理解能力:
- 这是阿里巴巴数据岗位最核心的要求之一,阿里强调“数据是业务的语言”,你需要能够理解你所服务的业务场景(如电商、金融、物流、云计算等),并能将数据洞察转化为可执行的业务建议。
- 能够站在产品和运营的角度思考问题,而不是仅仅停留在技术实现。
-
沟通与表达能力:
- 能够将复杂的技术问题或数据洞察,用清晰、简洁、易懂的语言向不同背景的同事(如产品经理、运营、高管)进行阐述。
- 良好的书面表达能力,能够写出逻辑清晰、结论明确的分析报告。
-
学习自驱力:
- 互联网行业技术日新月异,必须具备极强的学习能力和好奇心,能够快速掌握新技术、新工具。
- 有自驱力,能够主动发现问题并推动解决。
不同岗位的硬技能要求
阿里巴巴的数据岗位体系非常完善,主要分为以下几类:
数据分析师
这是业务中最贴近一线数据的岗位,要求“懂业务、会分析、能沟通”。
-
必备技能:
- SQL:必须精通,不仅是简单的增删改查,更要熟练掌握复杂的JOIN、子查询、窗口函数、CTE等,能够应对海量数据的高效查询。
- Python/R:熟练使用Python进行数据清洗、分析和可视化,核心库包括 Pandas, NumPy, Matplotlib, Seaborn。
- 数据可视化:熟练使用 Tableau 或 Superset 等BI工具,制作交互式仪表盘,同时也要能用Python进行高级可视化。
- 统计学知识:掌握描述性统计、假设检验、回归分析、A/B测试等基本统计方法,并能应用于实际业务场景。
-
加分项:
- 有用户增长、商业分析、运营分析等相关经验。
- 熟悉阿里内部的数据工具(如Quick BI, MaxCompute等)。
- 具备一定的机器学习知识(如用户画像、推荐系统原理)。
数据工程师
数据是生产资料,数据工程师负责“修路、建仓库”,确保数据高效、稳定、安全地流动和存储。
-
必备技能:
- 大数据技术栈:这是重中之重,必须精通 Hadoop, Spark, Flink 等分布式计算框架。
- 数据仓库/数据湖:深刻理解数据仓库(如 Hive)和数据湖(如 Hudi, Iceberg)的原理和设计,熟悉维度建模、星型模型等。
- 实时/离线数据开发:熟练掌握基于 DataWorks 等工具的离线数仓开发,以及基于 Blink/Flink 的实时计算任务开发。
- 消息队列:精通 Kafka, Pulsar 等消息队列,用于构建实时数据管道。
- 云原生技术:熟悉 Docker, Kubernetes (K8s),了解云原生大数据解决方案。
- 编程语言:Java/Scala 是主流,需要具备扎实的编程能力,用于开发复杂的ETL任务和数据处理服务。
-
加分项:
- 有大规模数据平台(日PB级数据处理)的设计和开发经验。
- 熟悉阿里云大数据产品(如MaxCompute, E-MapReduce, DataWorks)。
- 对数据治理、数据安全、数据质量有深入实践。
数据科学家/算法工程师
这是技术含量最高的岗位,要求“懂数据、精算法、能创新”,主要负责核心算法模型的研发和优化。
-
必备技能:
- 机器学习/深度学习:必须精通,熟悉各类经典机器学习算法(逻辑回归、GBDT、XGBoost等)和深度学习模型(CNN, RNN, Transformer等)的原理和应用。
- 数学基础:扎实的线性代数、概率论、微积分和最优化理论功底。
- 特征工程:具备从海量数据中提取有效特征、构建高质量特征集的丰富经验。
- 模型工程化:了解如何将模型高效地部署到生产环境,进行线上服务的A/B测试和效果监控。
- 主流框架:熟练使用 TensorFlow, PyTorch 等深度学习框架,以及 Scikit-learn 等机器学习库。
-
细分方向要求:
- 推荐系统:召回、排序、重排等全链路技术,协同过滤、深度学习推荐模型等。
- 计算机视觉:图像识别、目标检测、图像生成等。
- 自然语言处理:文本分类、情感分析、机器翻译、大语言模型等。
- 搜索算法:相关性、排序、Query理解等。
-
加分项:
- 在顶级学术会议(如NeurIPS, ICML, CVPR, ACL等)发表过论文。
- 在Kaggle等数据科学竞赛中取得优异成绩。
- 有将算法成功应用于大规模业务场景并取得显著效果的案例。
软技能与文化契合度
阿里巴巴非常看重“阿里味”,即与公司文化的契合度。
- 客户第一:一切工作以客户价值为出发点。
- 团队合作:乐于分享,善于协同,能够为了团队目标牺牲个人利益。
- 拥抱变化:在快速变化的环境中保持积极心态,能快速适应。
- 激情:对所从事的工作充满热情,有自驱力。
- 诚信:坚守职业道德,对数据负责。
招聘流程与面试重点
阿里巴巴的招聘流程通常包括以下几个环节:
- 简历筛选:HR和技术专家共同筛选,重点关注项目经验、技术栈匹配度和公司文化契合度。
- 在线笔试:主要考察数据结构、算法、SQL和Python编程能力,对于算法岗,还会有机器学习相关的理论题。
- 技术面试 (1-3轮):
- 深度技术面:考察岗位所需的核心技术能力,面试官会深入挖掘你简历上的每一个项目,问“为什么这么做”、“难点是什么”、“如何优化”,可能会现场手撕代码或设计题。
- 项目/业务面:考察你的业务理解能力和项目落地能力,面试官会模拟一个真实的业务场景,让你用数据分析或算法模型去解决。
- 交叉面试/总监面:
可能会与不同部门的总监或专家进行面试,考察你的综合能力、大局观和与团队的匹配度。
- HR面试:
考察你的职业规划、价值观、薪资期望等,确认你是否认同公司文化。
如何准备与建议
- 夯实基础:数据结构、算法、SQL、Python/Java 这些基础必须滚瓜烂熟。
- 深挖项目:对自己简历上的每一个项目都要了如指掌,能够清晰地阐述项目背景、你的角色、使用的技术、遇到的挑战以及最终的成果和反思。
- 理解业务:多研究阿里巴巴的业务(淘宝、天猫、阿里云、菜鸟等),思考这些业务背后的数据逻辑,可以尝试找一些公开的业务数据进行分析,形成自己的见解。
- 刷题与实战:
- 算法:在 LeetCode 上刷题,特别是中等难度的题目。
- SQL:多练习复杂查询,可以在 LeetCode 的 Database 题库中练习。
- 实战:在 Kaggle、天池等平台上参加竞赛,或者用公开数据集(如Kaggle上的E-commerce数据)做完整的分析项目,并整理到GitHub上。
- 熟悉阿里生态:如果可能,提前了解并学习阿里云的大数据产品(MaxCompute, DataWorks, E-MapReduce等)和开源组件,这会是巨大的加分项。
想加入阿里巴巴的数据团队,你需要成为一名“T型人才”:既有深度(某一领域的专业技术),又有广度(对业务的理解和跨领域的沟通协作能力),祝你成功!