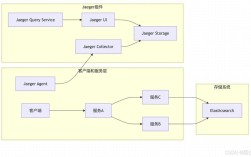
息壤数据库的管理是一个系统性工程,涉及数据模型设计、存储优化、权限控制、性能监控及安全防护等多个维度,其核心目标是实现数据的高效存储、安全访问与动态演进,以下从关键模块展开详细说明。

(图片来源网络,侵删)
数据模型设计与版本管理
息壤数据库采用多模数据模型,支持关系型、文档型、图型等多种数据结构的统一存储,需通过逻辑分层设计实现灵活管理:
- 基础层:定义全局数据字典(如字段类型、约束规则),确保跨表数据结构一致性,用户表(
user)与订单表(order)通过user_id关联时,基础层会约束user_id的类型与外键级联规则。 - 业务层:按业务域划分数据子集(如电商域的“商品-库存-订单”链路),通过命名空间(namespace)隔离不同业务数据,避免交叉污染。
- 版本层:引入数据版本控制(DVC)机制,支持数据结构的向后兼容,当商品表新增
is_deleted字段时,旧版本数据可通过默认值补全,无需迁移存量数据。
| 版本管理策略 | 具体操作 | 适用场景 |
|---|---|---|
| 时间戳版本 | 为数据变更记录create_time、update_time,支持按时间范围回溯 |
需审计历史数据的业务(如金融) |
| 分支版本 | 类似Git的分支管理,支持创建数据分支(如“测试环境分支”“灰度分支”) | 多环境并行开发与测试 |
| 渐进式版本升级 | 通过中间层(如视图API)兼容旧版本接口,逐步迁移数据至新结构 | 大规模数据结构变更 |
分布式存储与分片策略
为应对海量数据,息壤数据库基于分布式架构设计,通过分片(Sharding)实现水平扩展:
- 分片键设计:选择高区分度、查询频繁的字段作为分片键(如
user_id、order_id),确保数据均匀分布,按user_id哈希取模分片,可避免单节点数据倾斜。 - 分片副本机制:每个分片默认部署3个副本(Replica),通过Raft协议保证数据一致性,当主节点故障时,副本自动切换,服务可用性达99.99%。
- 冷热数据分离:将访问频繁的热数据(如近3个月订单)存储在SSD节点,冷数据(如历史日志)迁移至低成本HDD节点,并通过生命周期策略自动触发数据流转。
权限控制与安全防护
数据安全是管理的核心,息壤数据库通过多维度权限体系实现精细化管控:
- 身份认证:支持基于RBAC(角色-Based访问控制)的权限模型,管理员可创建自定义角色(如“只读用户”“数据编辑员”),并绑定用户与权限。“财务角色”仅能访问
payment表,且无删除权限。 - 数据脱敏:对敏感字段(如身份证号、手机号)启用动态脱敏,查询时返回占位符,同时支持分级脱敏策略(如内部环境显示脱敏,生产环境加密存储)。
- 审计日志:记录所有数据操作(增删改查、权限变更),日志包含操作人、IP、时间、SQL语句等信息,支持实时告警与事后追溯。
性能监控与自动化运维
为保障系统稳定运行,息壤数据库构建了全链路监控体系:

(图片来源网络,侵删)
- 实时监控:通过Prometheus+Grafana采集节点性能指标(如CPU使用率、磁盘I/O、QPS),设置阈值告警(如QPS超过5000时触发短信通知)。
- 慢查询优化:内置慢查询日志分析工具,自动定位低效SQL(如未走索引的查询),并生成优化建议(如添加联合索引)。
- 自动化运维:支持弹性伸缩(根据负载自动增减分片节点)、定时备份(全量备份+增量备份,备份保留30天)、故障自愈(副本故障自动重建,节点宕机自动迁移数据)。
相关问答FAQs
Q1:息壤数据库如何处理跨分片事务?
A:采用分布式事务协议(如TCC或Saga),将跨分片操作拆分为多个可补偿的子事务,创建订单时,先扣减库存(Try阶段),若成功则提交(Confirm阶段),失败则回滚(Cancel阶段),通过本地事务消息保证最终一致性,避免分布式事务阻塞。
Q2:数据迁移过程中如何保证业务连续性?
A:采用双写+流量切换方案:① 在旧库与新库同时写入数据,通过Canal同步binlog确保数据一致;② 新库上线后,先让小流量(如10%)走新库验证,监控无异常后逐步提升流量至100%;③ 旧库保留7天作为回滚缓冲,期间仅读不写,确保业务平滑过渡。

(图片来源网络,侵删)