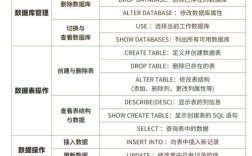
在sql中插入记录的命令是:INSERT INTO语句,这是关系型数据库管理系统中用于向指定表中添加新数据行的核心SQL命令,INSERT INTO语句的基本语法结构由表名、列名列表和待插入的值列表三部分组成,其标准形式为"INSERT INTO 表名 (列1, 列2, ..., 列n) VALUES (值1, 值2, ..., 值n)",当需要向表中插入完整记录时,如果列的顺序与表结构定义中的顺序完全一致,可以省略列名列表,直接使用"INSERT INTO 表名 VALUES (值1, 值2, ..., 值n)"的简化形式,但这种写法存在维护风险,不建议在生产环境中使用。

INSERT INTO语句在实际应用中具有多种灵活的变体形式,当只需要插入部分列的数据时,可以在列名列表中明确指定需要赋值的列,未指定的列将采用默认值(如果定义了DEFAULT约束)或NULL值(如果允许NULL),对于自增主键列(如MySQL中的AUTO_INCREMENT或SQL Server中的IDENTITY列),通常不需要在INSERT语句中指定值,数据库会自动生成唯一标识符,INSERT语句还支持多行插入语法,允许在单个语句中插入多组数据,这种写法在批量数据处理时能显著提高性能,其语法形式为"INSERT INTO 表名 (列1, 列2, ...) VALUES (值1a, 值2a, ...), (值1b, 值2b, ...), ..."。
在处理数据类型转换时,INSERT INTO语句需要特别注意不同数据库系统的类型兼容性规则,字符串类型的数据通常需要使用单引号括起来,日期类型的数据可能需要特定格式(如'YYYY-MM-DD'),数值类型则不需要引号,当插入的值与目标列的数据类型不匹配时,数据库会尝试进行隐式类型转换,但这种转换可能导致数据精度丢失或插入失败,因此推荐在应用程序层面进行显式类型转换,对于NULL值的处理,需要确保目标列允许NULL,否则插入操作将会失败,在某些数据库系统中(如Oracle),可以使用空字符串''代替NULL,但这种行为不具有普遍性。
事务控制是INSERT INTO语句使用中需要关注的重要方面,默认情况下,每条INSERT语句都是一个独立的事务,可以通过显式的事务控制语句(如BEGIN TRANSACTION、COMMIT、ROLLBACK)来管理多个插入操作的原子性,当需要确保一组插入操作要么全部成功要么全部失败时,可以将这些操作包含在同一个事务块中,在银行转账场景中,从一个账户扣款和向另一个账户存款这两个INSERT操作必须放在同一个事务中,以避免数据不一致,大多数数据库系统还提供了批量插入的优化机制,如MySQL的LOAD DATA INFILE命令或PostgreSQL的COPY命令,这些工具在处理大量数据时比逐行插入的效率高出几个数量级。
不同数据库系统对INSERT INTO语句的实现存在一些差异,MySQL支持INSERT...ON DUPLICATE KEY UPDATE语法,当插入的主键或唯一键已存在时,执行更新操作而不是报错,SQL Server提供了INSERT INTO...OUTPUT子句,允许将插入的数据返回给应用程序,Oracle则支持INSERT ALL语法,可以实现基于条件的多表插入,这些扩展功能使得INSERT语句在不同应用场景下能够更加灵活地满足业务需求,在日志记录系统中,可以使用INSERT IGNORE语句(MySQL)跳过重复键错误,确保日志记录的连续性。

在性能优化方面,批量插入时应尽量减少事务的提交频率,因为频繁的事务提交会增加磁盘I/O开销,对于支持批量操作的数据库,应优先使用批量插入语法而非循环执行单条INSERT语句,确保插入操作的表上有适当的索引也能提升性能,但需要注意,在大量数据插入时,临时禁用非关键索引可以提高速度,待数据插入完成后再重建索引,对于大型表的插入操作,考虑在低峰期执行,并监控系统的资源使用情况,避免对在线业务造成影响。
错误处理是INSERT INTO语句应用中不可或缺的部分,当插入操作违反约束条件(如主键冲突、外键约束、检查约束等)时,数据库会抛出异常,应用程序应当捕获这些异常并进行适当的处理,例如向用户提示错误信息或记录到日志中,在存储过程中,可以使用TRY...CATCH块(SQL Server)或异常处理机制(如PL/SQL中的EXCEPTION块)来管理插入过程中的错误,对于可能出现的并发问题,如死锁,应用程序可以实现重试逻辑,在遇到死锁错误后等待一段时间再重新执行插入操作。
数据验证是确保插入数据质量的关键环节,在应用程序层面,应在执行INSERT语句前对输入数据进行严格验证,包括数据类型、长度范围、格式校验等,电子邮件地址应验证其格式是否符合标准,数值字段应检查是否在允许的范围内,数据库层面的约束(如NOT NULL、UNIQUE、CHECK约束)是数据验证的最后一道防线,能够有效防止不符合业务规则的数据进入数据库,在设计表结构时,应合理定义约束条件,确保数据的完整性和一致性。
以下是INSERT INTO语句在不同场景下的应用示例表格:

| 应用场景 | SQL语句示例 | 说明 |
|---|---|---|
| 插入完整记录 | INSERT INTO employees (id, name, department, salary) VALUES (1, '张三', '技术部', 8000); | 向employees表插入包含所有列的新记录 |
| 插入部分列 | INSERT INTO employees (name, department) VALUES ('李四', '市场部'); | 只插入姓名和部门列,其他列采用默认值或NULL |
| 多行插入 | INSERT INTO products (id, name, price) VALUES (101, '笔记本', 4500), (102, '鼠标', 150), (103, '键盘', 300); | 一次性插入三条产品记录 |
| 插入默认值 | INSERT INTO orders (customer_id, order_date, status) VALUES (1001, '2023-10-01', DEFAULT); | status列使用默认值 |
| 插入查询结果 | INSERT INTO sales_archive (SELECT * FROM sales WHERE sale_date < '2023-01-01'); | 将查询结果插入到另一张表中 |
相关问答FAQs:
问:如何在使用INSERT INTO语句时避免重复键错误? 答:不同数据库系统提供了不同的解决方案,在MySQL中,可以使用INSERT IGNORE语句忽略重复键错误,或使用INSERT...ON DUPLICATE KEY UPDATE语法在遇到重复键时执行更新操作,在SQL Server中,可以使用MERGE语句实现"插入或更新"的逻辑,在PostgreSQL中,可以使用ON CONFLICT DO UPDATE子句,还可以在应用程序层面先查询是否存在记录,再决定执行插入还是更新操作。
问:INSERT INTO语句是否可以插入从其他表查询得到的数据? 答:是的,INSERT INTO语句支持子查询,可以将一个SELECT查询的结果插入到目标表中,语法形式为"INSERT INTO 目标表 (列1, 列2, ...) SELECT 列1, 列2, ... FROM 源表 WHERE 条件",这种写法在数据迁移、数据归档或数据汇总场景中非常有用,需要注意的是,目标表的列数和类型必须与SELECT查询返回的结果集兼容。"INSERT INTO archive_users (SELECT * FROM active_users WHERE last_login < '2022-01-01')"会将符合条件的活跃用户数据归档到archive_users表中。