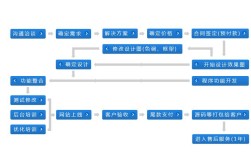
设计人工智能是一个复杂且多学科交叉的过程,需要从问题定义、数据准备、模型开发到部署维护的全流程规划,以下从核心步骤、关键技术考量、伦理设计及实践案例四个维度展开详细说明。

(图片来源网络,侵删)
问题定义与需求分析
设计AI的第一步是明确解决的具体问题,需将模糊的业务需求转化为可量化的技术目标,将图像分类准确率提升至95%”或“将客服机器人问题解决率提高至80%”,这一阶段需明确输入数据类型(文本、图像、语音等)、输出形式(分类、回归、生成等)以及性能指标(准确率、召回率、延迟等),需评估问题的可行性,例如是否存在足够数据、计算资源是否充足,以及是否符合行业法规(如医疗AI需符合FDA审批要求)。
数据准备与处理
数据是AI模型的“燃料”,其质量直接影响模型性能,流程包括:
- 数据收集:从公开数据集(如ImageNet)、企业数据库或传感器中获取数据,确保数据覆盖场景的多样性(如不同光照、角度的图像数据)。
- 数据清洗:处理缺失值(如用均值填充)、异常值(如剔除偏离均值3个标准差的数据)和重复数据,避免噪声干扰。
- 数据标注:监督学习需人工标注数据,例如图像分类需标注“猫”“狗”等标签,可采用工具如LabelImg或众包平台(如Amazon Mechanical Turk)。
- 数据增强:通过旋转、裁剪、添加噪声等方式扩充数据集,防止过拟合,在图像识别中,可将一张图片旋转10度生成新样本。
- 数据划分:将数据集按7:2:1比例划分为训练集(训练模型)、验证集(调参)和测试集(最终评估),确保数据分布一致。
以下为数据增强方法的示例表格:
| 数据类型 | 增强方法 | 工具/库 |
|---|---|---|
| 图像 | 旋转、翻转、色彩调整 | OpenCV, Albumentations |
| 文本 | 同义词替换、回译 | NLTK, Google Translate API |
| 语音 | 添加噪声、变速、变调 | Librosa, Audacity |
模型选择与开发
根据问题类型选择合适的模型架构:

(图片来源网络,侵删)
- 传统机器学习:结构化数据可选用逻辑回归(分类)、支持向量机(SVM)或XGBoost(特征工程要求低,适合表格数据)。
- 深度学习:非结构化数据更适合深度模型,
- 计算机视觉:CNN(如ResNet、YOLO用于目标检测)。
- 自然语言处理:Transformer(如BERT用于文本分类,GPT用于文本生成)。
- 时间序列预测:LSTM或GRU(如股票价格预测)。
模型开发需注意:
- 超参数调优:通过网格搜索或贝叶斯优化调整学习率、 batch size等参数。
- 正则化技术:使用Dropout(随机神经元失活)、L2正则化防止过拟合。
- 迁移学习:利用预训练模型(如BERT、VGG16)在小数据集上微调,减少训练时间和数据需求。
训练与评估
- 训练过程:使用GPU加速训练,监控损失函数(如交叉熵、MSE)和验证集指标,避免梯度消失(如使用ReLU激活函数)或爆炸(如梯度裁剪)。
- 评估指标:
- 分类任务:准确率、精确率、召回率、F1值(尤其适用于类别不平衡数据)。
- 回归任务:MAE(平均绝对误差)、RMSE(均方根误差)。
- 生成任务:BLEU(文本生成)、Inception Score(图像生成)。
- 交叉验证:通过k折交叉验证(如k=5)确保模型稳定性,避免单次数据划分的偶然性。
部署与监控
- 模型部署:将模型封装为API(如使用Flask、FastAPI),通过容器化(Docker)和容器编排(Kubernetes)实现弹性扩展,边缘设备(如手机)可使用TensorFlow Lite或ONNX格式压缩模型。
- 持续监控:跟踪模型性能衰减(如数据分布偏移导致的准确率下降),定期重新训练模型(如每月增量学习)。
- A/B测试:对比新旧模型在真实场景中的表现,例如推荐系统中测试不同算法的点击率。
伦理与安全设计
AI设计需兼顾公平性、透明度和鲁棒性:
- 公平性:避免算法偏见(如招聘模型歧视女性),可通过平衡训练数据(如过采样少数群体)或使用公平约束算法(如Adversarial Debiasing)。
- 可解释性:采用LIME(局部可解释模型)或SHAP值解释模型决策,尤其在医疗、金融等高风险领域。
- 鲁棒性:测试对抗样本(如添加微小扰动的图像导致模型误分类),使用对抗训练增强模型防御能力。
实践案例:智能医疗诊断系统
以肺癌CT影像诊断为例:
- 问题定义:实现肺结节良恶性分类,准确率≥90%。
- 数据:收集1000例CT影像,由3位医生标注,划分700训练、200验证、100测试集。
- 模型:采用ResNet-50作为 backbone,添加注意力机制聚焦结节区域。
- 训练:使用Adam优化器,学习率0.001,训练50个epoch,早停(验证集损失连续10次下降则停止)。
- 部署:通过DICOM协议接入医院PACS系统,API响应时间<500ms。
- 伦理:确保数据匿名化,模型解释模块提供“结节大小”“边缘特征”等依据。
相关问答FAQs
Q1: 如何解决小样本数据下的AI模型训练问题?
A: 可采用以下方法:(1)迁移学习:利用在大型数据集(如ImageNet)上预训练的模型,仅微调最后几层;(2)数据增强:通过生成对抗网络(GAN)合成新数据,如StyleGAN生成人脸图像;(3)少样本学习:使用元学习(如MAML算法)或度量学习(如Siamese网络),让模型快速适应新类别。

(图片来源网络,侵删)
Q2: AI模型部署后性能下降怎么办?
A: 首先通过数据漂移检测(如KL divergence)判断输入数据分布是否变化;其次分析错误案例,若因新场景数据不足,需收集新数据并增量训练;若因模型老化,可重新训练或采用集成学习(如结合多个模型预测),优化部署环境(如升级硬件、减少延迟)也能提升实时性能。