HDFS的get命令是Hadoop分布式文件系统中最常用的命令之一,主要用于将HDFS上的文件或目录下载到本地文件系统中,该命令是HDFS文件操作体系中的核心工具,尤其在数据迁移、备份和本地分析等场景中发挥着重要作用,与put命令相对应,get命令实现了从分布式文件系统到本地文件系统的数据传输,其底层依赖于Hadoop的RPC机制和HDFS的数据块复制策略,确保数据传输的高效性和可靠性。

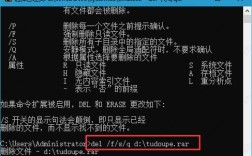
从基本语法来看,hdfs dfs -get命令的格式为hdfs dfs -get [-f] [-p] <src> <localdst>,其中<src>表示HDFS上的源文件或目录路径,<localdst>表示本地文件系统中的目标路径。-f参数用于覆盖已存在的本地文件,当目标文件存在时,系统会提示用户确认,而加上-f则可以直接覆盖,无需交互式确认。-p参数则用于保留源文件的权限、时间戳等属性,这在需要保持文件元数据一致性的场景中非常有用,例如在跨环境部署时保留原始文件的权限设置,需要注意的是,如果源路径是一个目录,使用get命令时会将该目录及其所有子文件和子目录递归下载到本地,但此时必须确保目标路径是一个不存在的目录或是一个已存在的空目录,否则会报错。
在功能特性方面,hdfs dfs -get命令支持多种文件类型的处理,对于普通文件,get命令会直接将文件内容下载到本地,并保持原始的文件内容不变,对于符号链接,get命令会跟随链接指向的实际文件进行下载,而不是下载链接本身,get命令还支持大文件的分块下载,由于HDFS中的文件被切分为多个数据块存储在不同的DataNode上,get命令在下载时会并行从多个DataNode获取数据块,最后在本地合并成完整的文件,这种机制大大提高了大文件的下载效率,一个1GB的文件在HDFS中被划分为128个128MB的数据块,get命令可以同时从多个DataNode下载这些数据块,充分利用网络带宽,缩短下载时间。
性能优化是get命令使用过程中的重要考量因素,当下载大文件或大量小文件时,可以通过调整Hadoop的配置参数来优化传输性能。io.file.buffer.size参数控制了本地文件系统的缓冲区大小,适当增大该值(如从默认的4096字节调整为65536字节)可以提高本地I/O效率。dfs.client.read.prefetch.limit参数设置了预读取的数据块大小,增大该值可以让客户端提前读取后续数据块,减少等待时间,在网络环境较差的情况下,可以通过调整dfs.replication参数降低数据块的副本数,但需要注意这可能会影响数据的可靠性,对于集群管理员,还可以通过启用压缩功能(如使用Snappy或Gzip压缩)来减少网络传输的数据量,但会增加客户端的解压开销。
错误处理机制是get命令可靠性的重要保障,在下载过程中,如果某个数据块传输失败,Hadoop会自动尝试从其他副本所在的DataNode重新获取该数据块,最多重试三次,如果三次重试均失败,命令会返回错误信息并终止下载,get命令还会校验文件的校验和,确保下载的文件内容与HDFS上的原始文件完全一致,如果校验和不匹配,说明文件在传输过程中发生了损坏,Hadoop会删除已下载的部分文件并提示用户重新下载,在实际使用中,用户可以通过查看Hadoop的日志文件来定位具体的错误原因,例如权限不足、磁盘空间不足或网络中断等问题。

与get命令相关的其他实用功能包括-crc选项和-skipcrccheck选项。-crc选项会在下载文件的同时生成一个.crc文件,该文件包含了文件的校验和信息,用于后续验证文件的完整性。-skipcrccheck选项则跳过校验和检查,适用于对文件完整性要求不高的场景,可以略微提高下载速度,get命令还支持将HDFS文件下载到标准输出,例如使用hdfs dfs -get <src> -可以将文件内容输出到终端,常用于查看文件内容或通过管道将文件内容传递给其他命令处理。
在实际应用场景中,get命令被广泛用于数据备份和迁移,当需要将HDFS上的数据备份到本地存储设备时,可以使用get命令将整个目录结构下载到本地磁盘,在数据分析场景中,数据科学家经常将HDFS上的原始数据下载到本地工作站,使用Python、R等工具进行数据清洗和建模,在跨集群数据迁移时,可以通过get命令将源集群的数据下载到本地,再通过put命令上传到目标集群,实现数据的平滑迁移,需要注意的是,在下载大文件时,应确保本地有足够的磁盘空间,并监控磁盘使用情况,避免因磁盘空间不足导致下载失败。
以下是get命令使用过程中常见问题的解答:
FAQs:
-
问:使用hdfs dfs -get命令下载文件时,提示“Permission denied”错误,如何解决?
答:该错误通常是由于当前用户对HDFS上的源文件没有读取权限导致的,可以通过以下步骤解决:首先使用hdfs dfs -chmod命令修改源文件的权限,例如hdfs dfs -chmod 644 /path/to/file将文件权限设置为所有者可读写、其他用户只读;然后使用hdfs dfs -chown命令修改文件的所有者,例如hdfs dfs -chown username:groupname /path/to/file将文件所有者改为当前用户,确保当前用户在HDFS上有足够的权限访问源文件所在的目录。 -
问:下载大文件时,get命令速度很慢,有哪些优化方法?
答:优化下载速度可以从多个方面入手:检查网络带宽是否充足,确保客户端与Hadoop集群之间的网络连接稳定;调整Hadoop配置参数,如增大io.file.buffer.size和dfs.client.read.prefetch.limit的值;如果文件较大,可以尝试将文件拆分为多个小文件并行下载,或者使用-D dfs.blocksize参数调整数据块大小以减少网络传输次数;可以考虑启用数据压缩,减少网络传输的数据量,但需要注意客户端的解压能力,如果集群支持,还可以使用DistCp工具进行分布式复制,提高下载效率。