HBase 是一种基于 Hadoop 的分布式、面向列的 NoSQL 数据库,适用于存储海量稀疏数据,掌握其基本命令是高效操作 HBase 的关键,以下从表操作、数据操作、命名空间管理和高级命令四个维度详细介绍 HBase 常用命令。

表操作命令
表是 HBase 数据存储的核心单元,相关命令包括创建、查看、修改和删除表。
-
创建表
使用create命令创建表,需指定表名和列族(至少一个列族),列族名需以字母开头,可包含字母、数字、下划线,长度不超过 255 字节。create 'table_name', 'column_family1', 'column_family2'
示例:创建用户表
user_info,包含base_info和extend_info两个列族:create 'user_info', 'base_info', 'extend_info'
-
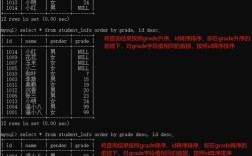
查看表列表
list命令用于列出所有表,支持正则表达式过滤。 (图片来源网络,侵删)
(图片来源网络,侵删)list 'table_name_pattern' # list 'user.*' 匹配所有以 user 开头的表
-
查看表结构
describe命令显示表的详细结构,包括列族、版本数、TTL(存活时间)等信息。describe 'table_name'
输出示例:
Table user_info is ENABLED COLUMN FAMILIES DESCRIPTION {NAME => 'base_info', VERSIONS => '1', TTL => 'FOREVER', BLOCKSIZE => '65536', BLOOMFILTER => 'ROW'} {NAME => 'extend_info', VERSIONS => '3', TTL => '2592000', BLOCKSIZE => '65536', BLOOMFILTER => 'ROW'} -
修改表结构
- 添加列族:使用
alter命令新增列族,需先禁用表。disable 'table_name' alter 'table_name', 'NAME' => 'new_column_family' enable 'table_name'
- 删除列族:同样需先禁用表,再指定列族并添加
METHOD => 'delete'。disable 'table_name' alter 'table_name', 'NAME' => 'column_family_to_delete', METHOD => 'delete' enable 'table_name'
- 添加列族:使用
-
启用/禁用表
禁用表后无法进行读写操作,但可修改结构;启用表后恢复正常操作。disable 'table_name' # 禁用表 enable 'table_name' # 启用表
-
删除表
删除表前必须先禁用表,否则会报错。disable 'table_name' drop 'table_name'
数据操作命令
HBase 数据以行键(RowKey)、列族(Column Family)、列限定符(Column Qualifier)、时间戳(Timestamp)四维坐标存储,操作命令包括增、删、改、查。
-
插入/更新数据
使用put命令插入或更新数据,需指定行键、列族、列限定符及值,若行键和列已存在,则更新数据(默认覆盖旧值)。put 'table_name', 'row_key', 'column_family:column_qualifier', 'value'
示例:向
user_info表插入用户user001的姓名和年龄:put 'user_info', 'user001', 'base_info:name', 'Alice' put 'user_info', 'user001', 'base_info:age', '25'
-
查询数据
- 单行查询:
get命令查询指定行的数据,可指定列族或列限定符过滤。get 'table_name', 'row_key' # 查询整行数据 get 'table_name', 'row_key', 'column_family:column_qualifier' # 查询指定列
示例:查询
user001的姓名:get 'user_info', 'user001', 'base_info:name'
- 范围扫描:
scan命令扫描多行数据,支持行键范围、列族、过滤器等条件。scan 'table_name', {STARTROW => 'start_row_key', ENDROW => 'end_row_key'} scan 'table_name', {COLUMN => 'column_family:column_qualifier'}示例:扫描
user_info表中行键从user001到user003的数据:scan 'user_info', {STARTROW => 'user001', ENDROW => 'user003'}
- 单行查询:
-
删除数据
- 删除指定列:
delete命令删除某一列的最新版本数据(默认删除所有版本)。delete 'table_name', 'row_key', 'column_family:column_qualifier'
- 删除整行:
deleteall命令删除行的所有数据。deleteall 'table_name', 'row_key'
- 删除指定列:
命名空间管理命令
命名空间(Namespace)用于隔离不同表,类似数据库中的 schema,默认命名空间为 default。
-
创建命名空间
create 'namespace_name'
示例:创建
user_db命名空间:create 'user_db'
-
查看命名空间
list_namespace # 列出所有命名空间
-
在命名空间下操作表
创建或操作表时,可通过namespace:table_name指定命名空间。create 'user_db:user_info', 'base_info' # 在 user_db 下创建 user_info 表 list 'user_db:.*' # 查看 user_db 下的所有表
高级命令
-
计数统计
count命令统计表中的行数,支持并行扫描,速度较快。count 'table_name'
-
清空表数据
truncate命令清空表数据,并重置表结构(包括列族配置),操作前会禁用表。truncate 'table_name'
相关问答FAQs
Q1: HBase 中如何批量插入数据?
A1: HBase 本身不支持批量插入的 batch put 命令,但可通过以下方式实现批量操作:
- 使用 MapReduce 批量导入:通过 HBase 的 TableInputFormat 和 TableOutputFormat,结合 MapReduce 批量读取 HDFS 数据并写入 HBase。
- 使用 API 批量提交:在 Java API 中,通过
BufferedMutator接口实现批量写入,减少网络开销,示例代码:Connection connection = ConnectionFactory.createConnection(config); BufferedMutator mutator = connection.getBufferedMutator(TableName.valueOf("table_name")); Put put = new Put(Bytes.toBytes("row_key")); put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("col"), Bytes.toBytes("value")); mutator.mutate(put); mutator.flush(); // 提交批量数据
Q2: HBase 表的 RowKey 设计有什么原则?
A2: RowKey 是 HBase 数据检索的核心,设计需遵循以下原则:
- 唯一性:确保每行数据的 RowKey 唯一,避免数据覆盖。
- 长度原则:RowKey 长度尽量短(10-100 字节),过长会占用存储空间并影响查询效率。
- 散列性:避免 RowKey 集中(如时间戳直接作为 RowKey 会导致写热点),可通过加盐(添加随机前缀)、哈希或反转等方式分散。
- 有序性:如果范围扫描是主要查询场景,RowKey 应按字典序有序(如手机号、用户 ID 等)。
用户 ID 为1001,加盐后 RowKey 可为salt_1001(salt 为随机前缀),避免写热点。