Linux系统巡检是保障服务器稳定运行的重要环节,通过定期检查系统状态、资源使用、服务运行等情况,可以及时发现潜在问题并进行处理,以下从系统基本信息、CPU、内存、磁盘、网络、进程、日志及服务等多个维度,详细介绍常用的Linux系统巡检命令及使用方法。

(图片来源网络,侵删)
系统基本信息巡检
查看系统版本、内核信息、运行时间等基本信息,有助于快速了解系统环境。
- 查看系统发行版信息:
cat /etc/os-release:显示详细的发行版信息,如Ubuntu、CentOS等版本号。
lsb_release -a:显示LSB(Linux Standard Base)信息,需安装lsb-core包。 - 查看内核版本:
uname -a:显示内核名称、版本、主机名等信息;uname -r仅显示内核版本。 - 查看系统运行时间:
uptime:显示系统运行时间、当前用户数及负载平均值(1分钟、5分钟、15分钟)。 - 查看主机名:
hostname:显示或设置主机名;hostnamectl(systemd系统)可查看详细主机信息。
CPU资源巡检
CPU是系统的核心资源,需重点关注使用率、负载及进程占用情况。
- 查看CPU使用率:
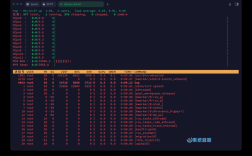
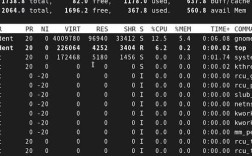
top:动态显示进程及CPU使用率,按1可查看各核心使用情况。
htop:比top更友好的交互式工具,支持彩色显示和鼠标操作(需安装)。
vmstat 1 5:每秒更新一次,共5次,显示CPU系统、用户、空闲等时间占比。 - 查看CPU负载:
uptime:已提及,可快速查看系统负载,负载值应不超过CPU核心数。
mpstat -P ALL 1:显示各CPU核心的详细使用情况。 - 查看CPU信息:
lscpu:显示CPU架构、核心数、线程数等详细信息;cat /proc/cpuinfo查看原始CPU信息。
内存巡检
内存不足会导致系统性能下降,需检查内存使用情况及缓存占用。
- 查看内存使用量:
free -h:以人类可读格式(GB/MB)显示内存、交换空间使用情况,-m/-k可指定单位。
top:按M按内存使用率排序进程,或直接查看“Mem”行数据。 - 查看内存详情:
vmstat:显示swap分区使用情况,若si(swap入)和so(swap出)值持续较高,说明内存不足。
cat /proc/meminfo:查看内存详细参数,如总内存、可用内存、 buffers、cached等。
磁盘巡检
磁盘空间不足或I/O性能问题会影响系统运行,需检查磁盘使用率、inode及I/O性能。

(图片来源网络,侵删)
- 查看磁盘使用率:
df -h:显示各分区挂载点、总容量、已用空间、可用空间及使用率,-i可查看inode使用情况。
du -sh *:查看当前目录下各文件及文件夹大小,-h可指定人类可读格式。 - 查看磁盘I/O性能:
iostat -xz 1:显示磁盘设备、util(I/O利用率)、r/s(读请求数)、w/s(写请求数)等,util超过70%可能存在I/O瓶颈。
iotop:类似top的磁盘I/O监控工具,可实时显示各进程的I/O占用(需安装)。 - 查看磁盘信息:
lsblk:显示块设备信息,包括磁盘分区、挂载点等;fdisk -l查看磁盘分区表。
网络巡检
网络问题可能导致服务不可达,需检查网络连接、端口及流量情况。
- 查看网络连接:
netstat -tuln:显示监听端口及协议(-t TCP,-u UDP,-l 仅监听,-n 不解析域名)。
ss -tuln:比netstat更高效,显示socket连接状态。 - 查看网络接口流量:
iftop:实时显示网络接口的实时流量、连接数等(需安装);nethogs按进程显示网络流量(需安装)。 - 查看路由表及DNS:
route -n:显示路由表;cat /etc/resolv.conf查看DNS配置;ping 8.8.8.8测试网络连通性。 - 抓包分析:
tcpdump -i eth0 port 80:抓取eth0接口80端口的网络数据包(需安装tcpdump)。
进程巡检
异常进程可能消耗系统资源或存在安全风险,需关注进程状态、资源占用及启动时间。
- 查看进程状态:
ps -ef:显示所有进程的详细信息;ps aux:显示进程CPU、内存占用情况。
pgrep -f "nginx":查找包含“nginx”关键词的进程ID。 - 查看实时进程:
top/htop:动态刷新进程列表,可按CPU/内存排序,查看进程资源占用。 - 终止进程:
kill -9 PID:强制终止进程;killall nginx:通过进程名终止所有nginx进程。
日志巡检
系统日志记录了系统运行的关键信息,通过日志可定位故障原因。
- 查看系统日志:
journalctl -xe:查看systemd日志,-x显示详细信息,-e显示最新日志;tail -f /var/log/syslog(Ubuntu)或/var/log/messages(CentOS)实时查看系统日志。 - 查看应用日志:
tail -f /var/log/nginx/access.log:查看Nginx访问日志;grep "error" /var/log/mysql/error.log过滤MySQL错误日志。 - 日志轮转情况:
ls -lh /var/log/*.log.*:查看日志轮转文件,避免日志过大占用磁盘空间。
服务巡检
系统服务是否正常运行直接影响业务可用性,需检查服务状态及开机自启。

(图片来源网络,侵删)
- 查看服务状态:
systemctl status nginx:查看nginx服务状态(active为运行);service --status-all查看所有服务状态。 - 启用/禁用开机自启:
systemctl enable nginx:设置nginx开机自启;systemctl disable firewalld:禁用防火墙开机自启。 - 查看端口监听:
lsof -i :80:查看80端口被哪个进程占用;netstat -tuln | grep 80检查80端口是否监听。
常用巡检命令速查表
| 检查维度 | 常用命令 | 说明 |
|---|---|---|
| 系统信息 | cat /etc/os-release |
查看系统发行版 |
uname -r |
查看内核版本 | |
| CPU | top(按1) |
动态查看CPU及各核心使用率 |
mpstat -P ALL 1 |
查看各CPU核心详细使用情况 | |
| 内存 | free -h |
查看内存及交换空间使用情况 |
vmstat |
查看内存swap及系统状态 | |
| 磁盘 | df -h |
查看分区使用率 |
iostat -xz 1 |
查看磁盘I/O性能 | |
| 网络 | ss -tuln |
查看监听端口及连接状态 |
iftop |
实时查看网络流量 | |
| 进程 | ps aux |
查看进程资源占用 |
htop |
交互式进程管理 | |
| 日志 | journalctl -xe |
查看系统日志 |
tail -f /var/log/syslog |
实时查看系统日志 | |
| 服务 | systemctl status nginx |
查看服务状态 |
lsof -i :80 |
查看端口占用进程 |
相关问答FAQs
Q1: 如何判断Linux系统是否存在内存泄漏?
A1: 判断内存泄漏可通过以下步骤:
- 定期对比内存使用:使用
free -h记录系统可用内存,若重启后内存恢复正常,但运行一段时间后可用内存持续减少,可能存在内存泄漏。 - 检查缓存占用:运行
cat /proc/meminfo查看Slab和Cached值,若Slab持续增长且不释放,可能是内核模块或应用内存泄漏。 - 分析进程内存:使用
ps aux --sort=-%mem按内存占用排序进程,观察可疑进程的RES(实际内存)是否持续增长;结合pmap -x PID查看进程内存映射,定位异常模块。 - 工具辅助:使用
smem工具分析进程内存占用,或通过valgrind(需安装)对可疑进程进行内存泄漏检测。
Q2: Linux系统负载过高时,如何快速定位问题原因?
A2: 系统负载过高(如负载值超过CPU核心数)时,可按以下步骤快速定位:
- 查看负载来源:运行
top按P(CPU使用率)或M(内存使用率)排序,找出占用资源最高的进程,若CPU占用高,可能是计算密集型进程;若内存占用高,可能是内存泄漏或频繁swap。 - 检查CPU类型:运行
vmstat 1,观察us(用户进程)、sy(系统进程)、wa(I/O等待)、id(空闲)值,若us高,检查用户进程;sy高,可能是内核问题;wa高,需检查磁盘I/O。 - 分析磁盘I/O:运行
iostat -xz 1,若%util(I/O利用率)接近100%,说明磁盘瓶颈,可通过iotop查找占用I/O的进程。 - 检查网络:若负载伴随网络异常,运行
iftop或netstat -an查看网络连接数,是否因DDoS攻击或连接数过多导致。 - 日志排查:查看
/var/log/messages或journalctl,结合时间定位错误日志,如OOM(内存不足) killer日志、内核错误等。