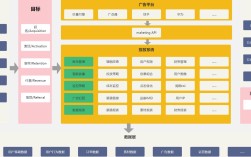
前端开发技术选型
| 类别 | 主流方案 | 适用场景/优势 |
|---|---|---|
| HTML/CSS框架 | Bootstrap、Tailwind CSS | 响应式布局快速实现;Tailwind支持原子化样式设计 |
| JavaScript库 | React(函数组件+Hooks)、Vue.js(Composition API)、Svelte | 组件化开发效率高;Svelte编译优化性能更优 |
| CSS预处理器 | Sass/Less | 变量管理、嵌套规则、混合宏定义提升可维护性 |
| 交互增强 | Webpack打包工具链 + Babel转译 | ES6+语法兼容旧浏览器;Tree Shaking减少包体积 |
| UI组件库 | Ant Design、Element UI、Material UI | 开箱即用的标准化控件库,降低重复造轮子成本 |
注:移动端优先建议采用PWA(渐进式网页应用)技术,通过Service Workers实现离线缓存与推送通知功能。
(图片来源网络,侵删)

后端架构设计要点
编程语言对比
| 语言 | 典型框架 | 部署复杂度 | 社区生态成熟度 | 高并发处理能力 |
|---|---|---|---|---|
| Node.js | Express/Koa | 低 | 依赖集群管理 | |
| Python | Django/Flask | 中 | Gunicorn+Nginx调优 | |
| Java | Spring Boot | 高 | Tomcat容器化天然支持垂直扩展 | |
| Go | Gin/Echo | 极低 | 新兴但增长迅速 | goroutine轻量级协程模型 |
API规范标准
- RESTful原则:使用HTTP方法语义化操作资源(GET/POST/PUT/DELETE),URL路径携带版本号(如
/v1/users) - OpenAPI文档:通过Swagger UI自动生成接口测试页面,确保前后端契约一致性
- 安全防护层:JWT令牌鉴权 + CORS跨域限制 + Helmet安全中间件防注入攻击
数据库配置策略
| 类型 | 推荐方案 | 备份机制 | 扩展方案 |
|---|---|---|---|
| 关系型 | PostgreSQL主从复制 | 物理快照+逻辑增量备份 | Read Replica读写分离 |
| NoSQL | MongoDB分片集群 | Oplog日志回放 | Sharding键合理分布数据 |
| 缓存层 | Redis哨兵模式主备切换 | RDB持久化+AOF日志 | Lua脚本实现复杂业务逻辑 |
服务器部署方案对比表
| 云服务商 | 基础配置示例 | CDN加速节点覆盖 | 全球延迟表现 | 运维成本指数 |
|---|---|---|---|---|
| AWS Lightsail | t3.medium实例+50GB SSD | CloudFront全球边缘节点 | <150ms(亚太区) | 中等偏低 |
| Alibaba Cloud ECS | c5.large规格族 | DCDN动态路由解析 | 80~120ms(国内) | 本地化支持优秀 |
| Vercel | Next.js框架自动优化 | Edge Network智能预加载 | Frontend优先加速 | Serverless免运维 |
| DigitalOcean Droplet | SFO1数据中心KVM虚拟化 | Quic协议压缩传输 | NA地区最优选择 | DIY灵活性最高 |
关键决策因素:目标用户地域分布决定数据中心选址;预算有限时优先考虑按需付费模式(如Lambda@Edge)。
性能优化清单
✅ 前端侧重点:
- WebP/AVIF格式图片自适应编码
- Intersection Observer懒加载非首屏内容
- Workbox预缓存静态资源哈希指纹版本
- Brotli压缩算法启用(Nginx配置
brotli on;)
✅ 后端侧重点:
- SQL查询执行计划分析(EXPLAIN语句定位慢查询)
- gRPC替代JSON序列化降低带宽消耗
- Memcached分布式缓存热点数据碎片整理
- TLS加速特性启用(TLS_ECDHE优先级排序)
常见问题与解答(FAQ)
Q1:如何平衡新旧浏览器兼容性与现代Web特性使用?
答:采用渐进增强策略,通过@supportsCSS规则条件加载新特性,配合Babel的target参数设置目标浏览器版本范围,例如在package.json中指定"browserslist": ["last 2 versions", "not dead"],自动过滤掉IE11等过时环境,对于关键功能提供polyfill回退方案,如core-js库补全Promise API。

(图片来源网络,侵删)
Q2:当网站访问量突增时有哪些应急扩容手段?
答:①横向扩展增加应用实例数量,结合负载均衡器(ALB)分发流量;②启用数据库读写分离,将只读请求导向副本节点;③引入消息队列削峰填谷(Kafka消费延迟队列);④实施限流降级策略,对非核心路径返回缓存数据或错误码提示,具体实施时应先进行压力

(图片来源网络,侵删)