阿里HDFS招聘:技术深耕与生态协同的岗位需求解析

在云计算和大数据技术飞速发展的今天,分布式存储系统作为海量数据承载的核心基石,其技术能力与生态建设已成为企业数字化转型的关键支撑,阿里巴巴作为全球领先的科技企业,其自研的HDFS(Hadoop Distributed File System)不仅支撑着集团内部电商、金融、物流、云计算等核心业务的海量数据存储与计算需求,更通过阿里云对外输出,服务着全球数百万开发者与企业用户,阿里HDFS相关岗位的招聘始终聚焦于技术深度、工程能力与生态创新,旨在吸引和培养能够推动分布式存储技术持续突破的专业人才,以下从岗位方向、核心能力要求、技术栈体系及职业发展路径等多个维度,详细解析阿里HDFS招聘的内涵与方向。
岗位方向与核心职责
阿里HDFS团队的招聘岗位通常围绕技术研发、系统架构、工程效能和生态合作等方向展开,具体职责可分为以下几类:
-
核心开发工程师
负责HDFS底层存储引擎的迭代优化,包括高可用架构设计、读写性能调优、存储介质适配(如SSD、SMR)、元数据管理机制改进等,需深入理解Linux内核、I/O调度、网络协议栈等底层技术,解决大规模集群下的数据一致性、故障恢复、资源调度等核心问题,针对阿里云OSS-HDFS等混合存储场景,需设计跨协议数据迁移与分层存储策略,实现成本与性能的平衡。 -
分布式系统架构师
负责HDFS整体技术架构的规划与演进,设计面向万级节点、EB级数据的存储解决方案,需结合业务需求,引入如计算存储分离、Serverless存储、冷热数据分层等前沿架构,推动存储与计算引擎(如MaxCompute、Spark、Flink)的深度协同,需主导技术预研与原型验证,例如探索基于RDMA的低延迟通信优化、基于AI的智能存储调度等方向。 (图片来源网络,侵删)
(图片来源网络,侵删) -
性能优化与稳定性工程师
专注于HDFS集群的性能压测、瓶颈定位与稳定性保障,通过建立全链路监控体系(如基于Prometheus+Grafana的指标采集),分析慢查询、高延迟、丢包等问题的根因,推动内核级优化(如Page Cache机制改进、垃圾回收调优),需设计混沌工程测试方案,模拟各类故障场景(如节点宕机、网络分区),提升系统的自愈能力与SLA保障水平。 -
云存储产品与生态工程师
聚焦HDFS在阿里云上的产品化落地,负责OSS-HDFS、JindoFS等云存储功能的设计与迭代,需深入理解客户场景(如大数据分析、AI训练、在线业务),提供兼容HDFS协议的云存储解决方案,并推动开源社区合作(如Apache Hadoop、Apache Iceberg),实现技术生态的共建,需参与云存储SDK、工具链的开发,降低用户使用门槛。
核心能力要求与技术栈
阿里HDFS岗位对候选人的能力要求兼顾技术深度与广度,具体可分为硬技能与软技能两大类:
(一)硬技能要求
-
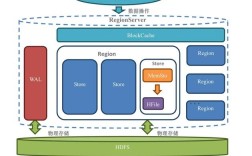
分布式系统基础
深入理解CAP理论、一致性协议(如Paxos、Raft)、数据分片与复制机制,熟悉HDFS架构(NameNode、DataNode、JournalNode等组件的设计与交互流程),需具备大规模分布式系统故障排查经验,例如通过分析Block元数据、EditLog定位数据不一致问题。 (图片来源网络,侵删)
(图片来源网络,侵删) -
编程语言与工具
精通Java(JUC并发包、JVM调优),熟悉C/C++(用于内核模块开发或性能优化);掌握Go语言者优先(用于云存储控制面开发),熟练使用Git进行代码管理,了解Maven/Gradle等构建工具,以及Shell/Python脚本开发能力。 -
存储与网络技术
熟悉Linux存储栈(VFS、文件系统、IO Scheduler)、网络协议(TCP/IP、RPC框架如Dubbo/gRPC),以及RAID、纠删码等数据冗余技术,对存储硬件(NVMe、SCSI、SMR)的特性与优化有实践经验者优先。 -
大数据与云原生技术
熟悉Hadoop生态(Hive、HBase、Kafka等),了解容器化(Docker、Kubernetes)与Serverless架构;有云存储服务(如AWS S3、Azure Blob)开发或优化经验者加分。
(二)软技能要求
- 问题解决能力:面对复杂技术难题,能通过逻辑拆解、数据分析定位根因,例如通过HDFS的审计日志分析异常访问模式。
- 团队协作与沟通:能与算法、工程、运维等跨团队角色高效协作,推动技术方案落地。
- 开源贡献:有Apache Hadoop、Apache Flink等开源项目贡献经验者优先,体现技术影响力。
(三)技术栈体系参考
| 技术领域 | 核心技术栈 |
|---|---|
| 分布式存储 | HDFS、Ceph、GlusterFS;纠删码、EC编码、分层存储 |
| 云原生 | Kubernetes、Service Mesh、Istio;容器存储接口(CSI) |
| 编程语言 | Java(JDK 8+)、C/C++、Go、Python |
| 监控与调优 | Prometheus、Grafana、Perf、eBPF;JVM调优、网络抓包(tcpdump/Wireshark) |
| 大数据生态 | Spark、Flink、MapReduce、Hive、Iceberg;数据湖存储方案 |
| 开发与运维工具 | Git、Jenkins、Ansible、Terraform;混沌工程工具(Chaos Mesh) |
职业发展与成长路径
阿里HDFS团队为人才提供清晰的职业发展通道,包括技术专家(T序列)与管理(M序列)双路径:
- 技术专家路径:初级工程师→高级工程师→资深工程师→专家→首席科学家,聚焦技术深度与创新突破,例如主导存储引擎重构或技术标准制定。
- 管理路径:技术负责人→项目经理→部门总监,聚焦团队建设与资源协调,推动跨部门技术战略落地。
阿里通过“阿里大学”、技术峰会(如云栖大会)、内部开源项目(如JindoFS)等平台,提供持续学习与成长机会,鼓励员工参与顶级会议(如OSDI、SOSP)论文发表,提升技术影响力。
相关问答FAQs
Q1:阿里HDFS岗位对学历和工作经验有何要求?是否接受应届生?
A1:阿里HDFS岗位对学历不作硬性限制,更看重技术能力与项目经验,核心开发、架构师类岗位通常要求3年以上分布式系统开发经验,熟悉HDFS源码者优先;应届生可投递“开发工程师(应届生)”岗位,需具备扎实的计算机基础(数据结构、操作系统、网络),有开源项目或竞赛经历(如ACM、Apache项目贡献)者加分,对于非应届生,如果有大规模集群运维或性能优化实战经验,即使非HDFS生态背景也有机会通过技术面试。
Q2:非Hadoop生态背景的候选人如何准备阿里HDFS岗位的面试?
A2:非Hadoop生态背景的候选人可通过以下路径提升竞争力:
- 夯实基础:系统学习《Hadoop权威指南》,掌握HDFS架构、读写流程、故障恢复机制;阅读HDFS源码(如NameNode元管理、DataNode心跳机制),理解核心模块设计。
- 实践项目:搭建本地Hadoop集群,实践数据导入(Hive、Sqoop)、性能测试(使用TeraSort基准测试)、故障模拟(NameNode Safe Mode切换),积累实操经验。
- 扩展技术视野:学习云存储(如AWS S3)、分布式数据库(如TiDB)相关技术,理解存储与计算分离架构;关注社区动态(如Hadoop 3.X的Erasure Code改进、云存储集成方案)。
- 面试准备:重点复习分布式系统原理(一致性、可用性、分区容错性)、Java并发编程(线程池、锁机制),以及场景题(如“如何设计10PB数据的存储系统以降低成本?”),通过阿里牛客网等平台刷题,提升算法与编码能力。