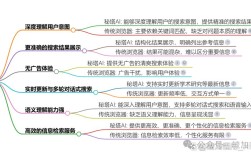
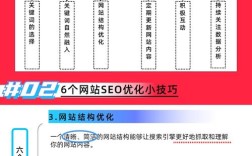
算四分位数(Q1、Q2/中位数、Q3)是描述数据分布特征的重要方法,适用于未分组或已排序的原始数据集,以下是详细的步骤解析和示例说明:

核心前提
✅ 必须先将数据从小到大排列(升序),这是计算所有分位数的基础,否则结果无意义,例如原始数据为 [7,3,9,1],需先整理为 [1,3,7,9]。
具体步骤与公式推导
确定位置指标(基于样本量n)
设数据集共有 n 个观测值,则三个关键位置分别为:
- 第一四分位 (Q₁) → 位于
(n+1)/4处 - 第二四分位 (Q₂/中位数) → 位于
(n+1)/2处 - 第三四分位 (Q₃) → 位于
3(n+1)/4处⚠️ 注意:当这些位置不是整数时,需采用线性插值法估算对应数值。
分情况讨论
| 情形类型 | 判断条件 | 处理方法 | 例示(n=7) |
|----------------|------------------------|--------------------------------------------------------------------------|-----------------------|
| A. 整数值位置 | 计算出的位置为整数 | 直接取该位置的数据作为分位数 | Q₂在(7+1)/2=4→第4个数 |
| B. 非整数值位置 | 计算出的位置含小数部分 | 找到相邻的两个整数索引k和k+1,按比例加权平均:Value = xₖ + f(x_{k+1}−xₖ)
(其中f为小数部分) | Q₁在(7+1)/4=2.0→精确匹配第二个数;若改为n=6则需插值 |

完整实例演示
以数据集 D = [6, 8, 12, 14, 15, 17, 19, 23](已排序,n=8)为例:
| 秩次 i | 数据值 xᵢ |
|---|---|
| 1 | 6 |
| 2 | 8 |
| 3 | 12 |
| 4 | 14 |
| 5 | 15 |
| 6 | 17 |
| 7 | 19 |
| 8 | 23 |
计算过程:
- Q₁定位: (8+1)/4 = 2.25 → 介于第2项与第3项之间
- 整数部分k=2,小数部分f=0.25
- Q₁ = x₂ + 0.25×(x₃−x₂) = 8 + 0.25×(12−8) = 8 + 1 = 9
- Q₂定位: (8+1)/2 = 4.5 → 在第4项和第5项中间
- k=4, f=0.5
- Q₂ = x₄ + 0.5×(x₅−x₄) = 14 + 0.5×(15−14) = 14 + 0.5 = 5
- Q₃定位: 3×(8+1)/4 = 6.75 → 落在第6项与第7项间
- k=6, f=0.75
- Q₃ = x₆ + 0.75×(x₇−x₆) = 17 + 0.75×(19−17) = 17 + 1.5 = 5
📌 验证合理性:四分位间距 IQR = Q₃−Q₁ = 18.5−9 = 9.5,说明中间50%数据的波动范围可控。
特殊场景处理技巧
▶︎ 偶数个vs奇数个数据的差异
| 数据规模 | 典型例子 | Q₂求法 | 备注 |
|---|---|---|---|
| 偶数n | n=8如上例 | 取中间两数的平均 | 无需额外调整 |
| 奇数n | n=7时D=[5,6,7,8,9,10,11] | 直接取第4个数即x₄=8 | 此时Q₁、Q₃也适用相同逻辑 |
▶︎ 重复值的影响
若存在多个相同值跨越分界点(如[1,2,2,2,3]),仍严格按位置计算,例如前例中若计算Q₁得2.3,则结果为2 + 0.3×(2−2)=2,不因重复而改变算法。
常见误区警示
❌ 错误做法1:忽略排序直接随机选取——导致完全错误的上文归纳。
❌ 错误做法2:用Excel的PERCENTILE函数默认模式替代手工计算——不同软件可能采用略有差异的算法(如Moore & McCabe vs Tukey推荐方法)。
❌ 错误做法3:对分组数据使用此方法——必须回归到原始未分组数据才能准确计算。
FAQs
Q1: 如果数据中有极端异常值怎么办?还能用四分位吗?
答:可以,四分位的优势在于其抗干扰性较强,不像均值那样易受极值影响,例如收入统计中常用Q₁~Q₃代替全距来规避亿万富翁样本点的扭曲效应,但需注意报告IQR时注明是否存在离群点。
Q2: 为什么不同教材给出的公式有时不一样?(比如有的用n而不是n+1)?
答:这源于两种主流学派的差异:① 基于“位置”的定义(支持n+1公式,认为每个数据点代表一个间隔);② 基于百分比的经验法则(直接使用n),实际应用中建议优先采用(n+1)版本,因为它能更精确地定位到具体的数据点或间隙,例如对于n=5的数据集,用(n+1)/4=1.5会比n/4=1更好地反映真实分布。
通过以上系统化的步骤拆解和实例验证,即使面对复杂数据集也能快速准确地手动计算出四分位数