添加数据到MySQL数据库可通过编写脚本定时执行INSERT语句、使用存储过程或触发器实现
是关于如何自动添加数据到MySQL数据库的详细说明:

(图片来源网络,侵删)
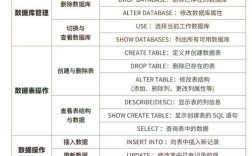
基础方法与核心语法
-
INSERT语句单行/多行插入
- 单行插入:使用标准
INSERT INTO语法,例如向employees表添加一名员工记录:INSERT INTO employees (first_name, last_name, age, department) VALUES ('John', 'Doe', 30, 'HR'); - 多行插入:通过逗号分隔多个值组实现批量写入,提升效率:
INSERT INTO employees (first_name, last_name, age, department) VALUES ('Jane', 'Smith', 25, 'IT'), ('Mike', 'Johnson', 40, 'Finance'), ('Emily', 'Davis', 35, 'Marketing');适用于少量或中等规模的数据录入场景,直接且易于控制。
- 单行插入:使用标准
-
LOAD DATA INFILE命令批量导入 此方法适合处理大规模结构化文本文件(如CSV):
LOAD DATA INFILE 'path/to/your/file.csv' INTO TABLE employees FIELDS TERMINATED BY ',' LINES TERMINATED BY 'n' (first_name, last_name, age, department);
需注意文件路径权限、字段匹配及特殊字符转义问题,该方式比逐条执行INSERT快数倍,常用于迁移历史数据或日志分析前的预处理。
 (图片来源网络,侵删)
(图片来源网络,侵删)
程序化与自动化方案
-
存储过程实现复杂逻辑封装 创建带参数的预编译代码块,支持动态调用:
DELIMITER // CREATE PROCEDURE AddEmployee( IN firstName VARCHAR(50), IN lastName VARCHAR(50), IN age INT, IN department VARCHAR(50) ) BEGIN INSERT INTO employees (first_name, last_name, age, department) VALUES (firstName, lastName, age, department); END // DELIMITER ; -调用示例 CALL AddEmployee('Alice', 'Brown', 28, 'Sales');优势在于可复用性高,并能集成业务规则校验(如薪资范围限制),适合作为API后端服务的基础组件。
-
循环脚本生成测试数据集 利用用户变量和流程控制语句批量造模拟数据:
DELIMITER // CREATE PROCEDURE InsertData() BEGIN DECLARE i INT DEFAULT 1; WHILE i <= 100 DO SET @employeeId = i; SET @employeeName = CONCAT('John', i); SET @employeeAge = FLOOR(RAND()(65-18+1))+18; -随机年龄区间 SET @employeeSalary = FLOOR(RAND()(10000-3000+1))+3000; -随机工资范围 INSERT INTO employees (id, name, age, salary) VALUES (@employeeId, @employeeName, @employeeAge, @employeeSalary); SET i = i + 1; END WHILE; END // DELIMITER ; CALL InsertData();可通过调整随机函数参数模拟不同分布特征的真实业务场景,快速构建开发环境所需的初始数据集。
高级优化策略
| 技术手段 | 适用场景 | 配置示例/实现方式 | 效果对比 |
|---|---|---|---|
| 禁用索引临时加速 | 千万级海量导入 | ALTER TABLE employees DISABLE KEYS;执行插入后启用键值 |
吞吐量提升,但牺牲即时查询能力 |
| 事务批量提交 | 高并发下的原子性操作集合 | START TRANSACTION;多条INSERT后 COMMIT; |
确保数据一致性 |
| 调整缓冲池大小 | 持续高压写入负载 | my.cnf设置innodb_buffer_pool_size=1G |
QPS显著上升 |
| ON DUPLICATE KEY更新 | 去重归并处理 | INSERT ... ON DUPLICATE KEY UPDATE ... |
避免主键冲突导致中断 |
生态工具链整合
- 图形界面辅助操作:MySQL Workbench提供可视化表单编辑功能,右键选择"Select Rows – Limit 1000"后直接修改单元格内容并点击Apply保存更改,此模式对非技术人员友好,适合偶尔的手工维护任务。
- PHPMyAdmin自动递增列管理:在表结构设计时勾选AI选项,后续插入时留空该字段即可自动填充序列值,常用于订单编号、自增ID等场景。
- Java程序化导入转储文件:通过JDBC读取SQL脚本文件并分段执行,典型实现包括驱动加载、连接建立、语句解析三个阶段,适用于生产环境的自动化部署流水线。
完整性保障机制
- 约束体系设计:定义外键关联(如部门ID引用部门主子表)、唯一性检查(邮箱不重复)、非空强制校验等结构性规则。
CREATE TABLE departments ( department_id INT AUTO_INCREMENT PRIMARY KEY, department_name VARCHAR(50) NOT NULL ); CREATE TABLE employees ( employee_id INT AUTO_INCREMENT PRIMARY KEY, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, age INT NOT NULL, department_id INT, FOREIGN KEY (department_id) REFERENCES departments(department_id) ); - 触发器审计日志:创建AFTER INSERT类型的触发器记录变更历史:
CREATE TRIGGER log_insert_employee AFTER INSERT ON employees FOR EACH ROW BEGIN INSERT INTO employee_log (employee_id, action, timestamp) VALUES (NEW.employee_id, 'INSERT', NOW()); END;此机制可追溯所有新增记录的操作时间和责任人,满足合规审计需求。
异常处理规范
- IGNORE忽略错误继续执行:当某些行因类型转换失败等原因无法插入时,使用
INSERT IGNORE跳过错误条目而非终止整个批次操作,适用于容错要求较高的数据采集环节。 - TRY...CATCH捕获运行时异常:在存储过程中嵌入错误处理逻辑,例如回滚事务或记录失败明细到专用表供后续排查,推荐结合LUA脚本实现更灵活的错误分类处置。
相关问答FAQs
Q1: 如果遇到主键冲突怎么办?如何实现“存在则更新”的逻辑?
A: 可以使用ON DUPLICATE KEY UPDATE子句。
INSERT INTO employees (employee_id, first_name, last_name, age, department) VALUES (1, 'John', 'Doe', 30, 'HR') ON DUPLICATE KEY UPDATE first_name = VALUES(first_name), last_name = VALUES(last_name), age = VALUES(age), department = VALUES(department);
当检测到主键已存在时,会自动执行指定的字段更新而非报错中断。
Q2: 如何监控批量导入的性能瓶颈?有哪些常用诊断工具?
A: 建议分阶段进行性能剖析:①使用EXPLAIN分析单条INSERT的执行计划;②开启慢查询日志定位耗时操作;③监控服务器级指标如InnoDB缓冲池命中率、磁盘I/O等待时间,专业场景可结合Percona Toolkit中的pt-query-digest工具深度解析慢日志,对于超大事务,考虑分批提交并观察Show Engine innodb status\G输出锁竞争