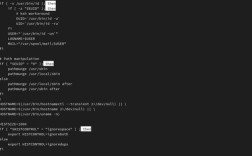
look 是一个在 Linux 和 Unix 系统中用于查找以特定字符串开头的行的命令,它通常被看作是 grep 命令的一个简化版本,专门用于“前缀匹配”。

(图片来源网络,侵删)
命令概述
look 命令的主要功能是:在一个已排序的文本文件中,快速查找所有以指定字符串开头的行。
核心特点:
- 速度快:由于要求数据源是已排序的,
look可以使用类似字典查找的高效算法(如二分查找),而不是逐行扫描,因此在处理大文件时速度非常快。 - 精确前缀匹配:它只查找以给定字符串开头的行,而不是包含该字符串的任意位置。
语法
look [选项] 字符串 [文件名]
参数说明
- 字符串:这是必需的参数。
look会查找所有以此字符串开头的行。 - 文件名:这是可选参数,如果省略,
look默认在/usr/share/dict/words文件(系统默认的字典文件)中查找,如果指定了文件名,则在该文件中查找。 - 选项:
-d或--alphanum:仅考虑字母和数字作为单词的组成部分,这可以忽略标点符号等,查找apple时,apple.和apple,也会被匹配。-f或--ignore-case:忽略大小写进行查找,查找hello会同时匹配Hello、HELLO等。-t或--terminate:指定一个字符作为字符串的终止符,默认情况下,字符串的终止符是换行符,这个选项用得较少。-V或--version:显示look命令的版本信息。-h或--help:显示帮助信息并退出。
常用示例
示例 1:基本用法(在系统字典中查找)
假设你想查找所有以 com 开头的单词。
look com
输出可能如下:

(图片来源网络,侵删)
comb
combine
combined
combing
coming
command
commander
commanding
...这会从系统的 /usr/share/dict/words 文件中输出所有以 com 开头的单词。
示例 2:在指定文件中查找
假设你有一个名为 names.txt 的文件,内容如下:
Alice
Bob
Charlie
David
Alice Cooper
Bob Dylan你想查找所有以 Bob 开头的行:
look Bob names.txt
输出:

(图片来源网络,侵删)
Bob
Bob Dylan示例 3:忽略大小写查找
使用 -f 选项来查找所有以 the 开头的单词,不区分大小写。
look -f the names.txt
names.txt 中有 The 或 THE,它们也会被匹配。
示例 4:仅匹配字母和数字
假设你有一个文件 data.txt如下:
apple
apple.
apple, pie
banana
banana-split
cherry使用 -d 选项查找以 apple 开头的行:
look -d apple data.txt
输出:
apple
apple.
apple, pie-d 选项告诉 look 将 apple 和 apple. 视为匹配,因为 不是字母或数字,被当作分隔符处理。
与 grep 命令的对比
这是理解 look 命令关键的一点。
| 特性 | look |
grep |
|---|---|---|
| 匹配模式 | 精确前缀匹配(以...开头) | 包含匹配(任意位置) |
| 速度 | 非常快(对已排序文件使用二分查找) | 相对较慢(需要逐行扫描,除非使用索引) |
| 数据要求 | 必须已排序 | 无要求,可以是任意文本文件 |
| 主要用途 | 快速查找字典、单词列表、按前缀分类的数据 | 强大的文本搜索、模式匹配、内容过滤 |
| 命令示例 | look apple words.txt |
grep apple words.txt |
举例说明区别:
对于文件 data.txt:
apple pie
pineapple
apple juice-
look apple data.txt的输出:apple pie apple juice只匹配以
apple开头的行。 -
grep apple data.txt的输出:apple pie pineapple apple juice匹配所有包含
apple字符串的行。
实际应用场景
- 拼写检查和单词补全:
look最经典的应用就是在系统字典中查找单词,用于实现简单的拼写检查或命令行自动补全功能。 - 查找用户名:在一个按字母顺序排序的用户列表中,快速查找所有以某个字母(如
a)开头的用户。 - 日志分析:如果你有一个按时间戳或某种ID排序的日志文件,并且你想查找以特定前缀(如
ERROR_2025-10-27)开头的所有错误日志,look会非常高效。 - 数据预处理:在处理大型数据集时,如果数据已经排序,可以使用
look快速提取某个类别下的所有记录。
注意事项
- 文件必须已排序:这是
look命令能够高效工作的前提,如果文件没有排序,look的输出将是不可预测的,并且速度优势也会消失,如果你不确定文件是否已排序,可以使用sort命令先对其进行排序:sort -o sorted_file.txt original_file.txt look apple sorted_file.txt
- 区分大小写:
look默认是区分大小写的。look Apple和look apple会得到不同的结果。
look 是一个简单、快速但功能非常专一的命令,当你需要在一个已排序的文件中执行前缀匹配时,它是比 grep 更高效的选择,对于通用的文本搜索,grep 或 egrep / fgrep 仍然是更强大、更灵活的工具。