整个过程可以分为两大步:

(图片来源网络,侵删)
- 配置图集采集规则:告诉织梦去哪个网站、怎么抓取图集。
- 执行采集并处理图片:运行采集任务,并确保图片能正确保存到你的服务器上。
第一步:配置图集采集规则
这是最核心的步骤,需要细心和耐心。
进入采集管理后台
登录你的织梦后台,在顶部菜单栏找到 “采集” -> “采集中心”,进入采集管理界面。
创建新的采集节点
在“采集中心”页面,点击 “增加新采集节点” 按钮。
填写节点基本信息
- 节点名称:给你的采集任务起个名字,方便识别,花瓣网美图采集”。
- 起始网址:这是最关键的一步! 你需要填写一个图集列表页的网址,这个页面应该包含多个你想要采集的图集的链接。
- 例如:花瓣网的某个搜索结果页、某个图集分类页。
- 织梦会自动分析这个页面,找出所有符合规则的图集链接。
- 目标站点:可以填写网站的名称,如“花瓣网”,也可以不填。
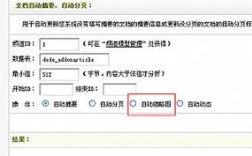
- 列表开始标记 和 列表结束标记:这是用来告诉织梦,在“起始网址”这个列表页中,从哪里开始、到哪里结束是图集列表的范围。
- 如何获取? 右键点击列表页中的一个图集链接 -> 选择“检查”或“审查元素” -> 在弹出的代码框中,找到这个链接所在的
<a>标签,向上找到包裹着所有图集链接的父级<div>或<ul>- 列表开始标记 就是这个父级标签的起始部分。
- 列表结束标记 就是这个父级标签的结束部分。
- 技巧:尽量使用
class或id来定位,这样更稳定,如果包裹列表的<div>的class是list,那么开始标记就可以写成<div class="list">。
- 如何获取? 右键点击列表页中的一个图集链接 -> 选择“检查”或“审查元素” -> 在弹出的代码框中,找到这个链接所在的
- 列表链接:这是用来提取单个图集网址的规则,通常填写
<a href='([url]+?)'这样的正则表达式,[url]是织梦内置的变量,代表链接地址。 - 分页设置:如果列表页有“下一页”,需要在这里设置分页规则,让织梦能抓取多页的列表。
- 分页开始标记 和 分页结束标记:和列表标记同理,找到“下一页”按钮所在的代码块。
- 下一页链接:提取“下一页”链接的规则,通常是
<a href='([url]+?)'。
配置图集内容页采集规则
这是采集图集的核心,你需要填写图集内容页的抓取规则。

(图片来源网络,侵删)
- 文章命名规则:设置采集回来的图集文章的标题,你可以使用
{list:title}(列表页标题)、{art:page}(页码) 等变量。{list:title}_{art:page}。 - 保存目录:选择图集要保存到的栏目。
- 作者:可以留空,也可以设置规则从页面抓取。
- 来源:可以留空,或者固定写“采集”。
- 缩略图:设置如何抓取图集的封面图。
- 抓取规则:右键图集封面图 -> 检查元素 -> 找到
<img>标签,提取src属性的规则。<img src='([url]+?)'。
- 抓取规则:右键图集封面图 -> 检查元素 -> 找到
- :这是图集采集最关键的部分。
- 内容区域开始标记 和 内容区域结束标记:找到包裹所有图片和说明文字的
<div>或<ul>- 内容分页:如果图集内容有多页(下一页”或“1/2 2/2”),需要设置分页规则,和列表页分页类似。
- 图片数量:设置这个图集总共有多少张图片,如果图片数量是固定的,可以写死一个数字;如果页面有显示总数,也可以尝试用规则抓取。
- 图片地址:设置如何抓取单张图片的URL,通常也是
<img src='([url]+?)'这样的规则。- 图片说明:设置如何抓取单张图片下方的说明文字,需要找到图片说明文字所在的
<p>或<span>标签,并提取其内容。<p class='desc'>([^<]+)</p>。
- 内容区域开始标记 和 内容区域结束标记:找到包裹所有图片和说明文字的
保存节点
填写完所有规则后,点击 “保存” 或 “测试” 按钮。强烈建议先点击“测试”,看看是否能正确抓取到图集标题、缩略图、图片数量等信息。
第二步:执行采集并处理图片
规则配置成功后,就可以开始采集了。
执行采集
在采集节点列表中,找到你刚刚创建的节点,点击后面的 “开始采集” 按钮。
- 织梦会先根据你设置的“列表规则”抓取所有图集链接。
- 然后会逐个打开这些链接,根据“内容规则”抓取图集的详细信息(图片和说明)。
- 你可以在页面下方看到采集进度和日志。
图片本地化(非常重要!)
采集完成后,你会发现图集文章是创建成功了,但图片地址还是别人的网站地址,一旦对方网站删除或修改图片,你的图集就显示不出来了。必须进行图片本地化。
-
使用织梦自带的“远程图片本地化”功能(推荐)
- 进入后台 “采集” -> “远程图片本地化”。
- 你可以选择“按栏目本地化”或“按文章本地化”。
- 选择你需要处理的栏目或文章,然后点击 “开始执行”。
- 织梦会自动扫描文章内容,将远程图片下载到你服务器的
/uploads/目录下,并替换文章中的图片地址为本地地址。
-
在采集时就进行本地化
- 在采集节点列表中,找到你的节点,点击 “修改”。
- 在“图集内容”设置区域,找到 “是否保存远程图片” 或类似的选项,务必勾选上。
- 确保你的 “保存目录” 和 “附件目录” 设置正确。
- 保存修改后,重新执行“开始采集”,这样采集过来的图片就已经是本地的了。
常见问题与技巧
-
采集不到图片或数量不对?
- 原因:通常是“图集内容”中的抓取规则写错了。
- 解决:回到“修改节点”页面,重新检查“内容区域标记”、“图片地址规则”、“图片说明规则”,多使用浏览器“检查元素”功能,确保规则精确匹配。
-
采集后图片显示不出来?
- 原因:绝大多数原因是图片没有本地化,或者远程服务器无法访问。
- 解决:务必使用“远程图片本地化”功能进行处理,检查你的服务器目录权限是否正确,确保
/uploads/目录可写。
-
采集速度很慢?
- 原因:采集是模拟浏览器访问对方网站,对方服务器响应慢、反爬虫机制都会导致速度慢。
- 解决:耐心等待,或者选择在服务器访问量较小的时候(如深夜)进行采集。
-
规则失效了怎么办?
- 原因:对方网站改版,HTML结构发生了变化。
- 解决:你需要重新进入“修改节点”页面,根据新的网页结构,重新抓取并设置所有的抓取规则。
织梦图集采集的流程可以概括为:
配置列表规则 -> 配置内容规则 -> 测试 -> 开始采集 -> 图片本地化
整个过程最考验的是耐心和细心,尤其是在编写和调试抓取规则时,多使用浏览器的开发者工具(F12)来分析网页结构,是成功采集的关键,祝你采集顺利!