wc 命令是 "Word Count"(字数统计)的缩写,它是一个在 Unix 和类 Unix 系统(如 AIX、Linux)中非常基础且强大的命令行工具,它的主要功能是统计指定文件中的行数、单词数、字节数和字符数。

基本语法
wc [选项]... [文件]...
- 选项: 用于指定统计的内容。
- 文件: 要统计的文件名,如果不指定文件,或者文件名是 ,则
wc会从标准输入读取数据。
常用选项及其说明
wc 命令的选项可以组合使用,以获取不同的统计信息。
| 选项 | 全称 | 说明 | 示例 |
|---|---|---|---|
-l |
--lines |
统计行数,这是最常用的选项之一。 | wc -l filename.txt |
-w |
--words |
统计单词数,单词以空白字符(空格、制表符、换行符等)分隔。 | wc -w filename.txt |
-c |
--bytes |
统计字节数,这是文件在磁盘上实际占用的空间大小。 | wc -c filename.txt |
-m |
--chars |
统计字符数,注意,这可能与字节数不同,尤其是在处理多字节字符(如中文)时。 | wc -m filename.txt |
-L |
--max-line-length |
统计最长行的长度(按字符数计算)。 | wc -L filename.txt |
基本使用示例
假设我们有一个名为 sample.txt 的文件,其内容如下:
Hello World. This is a test file. AIX is a robust OS.
统计行数 (-l)
$ wc -l sample.txt 4 sample.txt
输出显示 sample.txt 文件共有 4 行(包括一个空行)。
统计单词数 (-w)
$ wc -w sample.txt 13 sample.txt
输出显示文件中共有 13 个单词。

统计字节数 (-c)
$ wc -c sample.txt 70 sample.txt
输出显示文件共占用 70 个字节。
统计字符数 (-m)
对于这个纯 ASCII 文件,字符数和字节数是相同的。
$ wc -m sample.txt 70 sample.txt
重要区别: 如果文件包含多字节字符(如中文),-c 和 -m 的结果会不同。
示例:
创建一个包含中文字符的文件 chinese.txt为 你好,世界!。

你好,世界!共 5 个字符。- 在 UTF-8 编码下,每个中文字符通常占 3 个字节,标点符号 和 各占 3 个字节,总共
5 * 3 = 15个字节。
$ echo "你好,世界!" > chinese.txt $ wc -m chinese.txt 5 chinese.txt # 字符数 $ wc -c chinese.txt 15 chinese.txt # 字节数
统计最长行的长度 (-L)
$ wc -L sample.txt 21 sample.txt
输出显示文件中最长的一行有 21 个字符。
默认行为(不带选项)
当不使用任何选项时,wc 命令会默认同时显示行数、单词数、字节数和文件名。
$ wc sample.txt
4 13 70 sample.txt
这个输出格式非常清晰,依次是:行数 单词数 字节数 文件名。
高级使用技巧
同时统计多个文件
wc 命令可以一次性接受多个文件作为参数,它会分别统计每个文件,并在最后显示一个总计行。
$ wc -l sample.txt chinese.txt
4 sample.txt
1 chinese.txt
5 total
总计行显示总共有 5 行。
从标准输入读取数据
当 wc 命令没有指定文件,或者使用 作为文件名时,它会从标准输入读取数据,这在管道操作中非常有用。
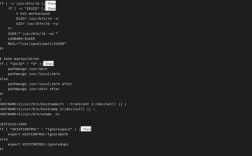
示例:统计当前目录下所有 .txt 文件的总行数
$ find . -name "*.txt" -exec wc -l {} \; | tail -1
5
解释:
find . -name "*.txt" -exec wc -l {} \;:查找所有.txt文件,并对每个文件执行wc -l。| tail -1:wc -l会为每个文件输出一行,最后还会输出一个总计行,我们只需要这个总计行,所以用tail -1来获取最后一行。
更简洁的写法(利用 wc 的总计行):
$ find . -name "*.txt" -exec wc -l {} + | tail -1
5
解释:
-exec ... +是find命令的一个更高效的用法,它会将找到的文件名作为一组参数传递给wc,而不是为每个文件单独启动一次wc。- 这样
wc只会输出一个总计行,我们再用tail -1提取它即可。
结合 here document 或 here string
$ wc -l <<EOF > line 1 > line 2 > line 3 > EOF 3
或者使用 here string:
$ wc -w <<< "This is a test string" 5
AIX 上的注意事项
wc 命令在 AIX 上的行为与在其他 Unix 系统(如 Linux)上基本一致,因为它们都遵循 POSIX 标准,但在一些细节上可能会有细微差别,尤其是在处理特定字符集或文件格式时。
- 默认编码: AIX 传统上使用其特定的编码(如 IBM-850),但现在也广泛支持 UTF-8,确保你的终端和文件编码一致,才能正确统计多字节字符(使用
-m选项)。 - 命令版本: AIX 自带的
wc是标准实现,功能完备,如果你从第三方源(如aixtoolbox)安装了更新版本的 GNU Coreutils,其行为可能会与原生版本有微小差异,但核心功能-l,-w,-c,-m,-L是完全一致的。
| 命令 | 功能 | 示例 |
|---|---|---|
wc |
默认统计行、词、字节 | wc file.txt |
wc -l |
仅统计行数 | wc -l file.txt |
wc -w |
仅统计单词数 | wc -w file.txt |
wc -c |
仅统计字节数 | wc -c file.txt |
wc -m |
仅统计字符数 | wc -m file.txt |
wc -L |
统计最长行长度 | wc -L file.txt |
掌握 wc 命令是进行日志分析、数据处理和脚本编写的基础技能,在 AIX 环境下,它同样是系统管理员和开发人员日常工作中不可或缺的工具。