什么是管道命令?
想象一下现实生活中的管道,它可以将一个地方的水输送到另一个地方,Shell 管道 () 的概念与此类似,但它传输的不是水,而是数据。

核心定义: 管道 () 是一个 Shell 操作符,它允许你将一个命令的标准输出 作为另一个命令的标准输入。
就是将前一个命令的执行结果,直接“喂”给后一个命令进行处理,而无需将结果保存到临时文件中。
语法格式:
command1 | command2 | command3 ...
工作流程:

command1执行,它产生的标准输出 不会显示在终端上。- 管道符 捕获这些输出。
command2开始执行,它从管道中读取command1的输出作为自己的标准输入。command2处理完毕后,它产生的标准输出又可以被下一个管道 捕获,交给command3处理。- 这个过程可以一直链接下去,形成一条“命令流水线”。
为什么需要管道?
管道的主要优势在于:
- 简洁高效:无需创建中间文件,直接在命令行中完成复杂的数据处理。
- 功能强大:可以将多个简单命令组合起来,完成单个命令难以实现的功能。
- 模块化:每个命令只做一件事,但做得很好,通过管道,你可以像搭积木一样组合它们,构建出复杂的解决方案。
管道的工作原理与标准流
要真正理解管道,需要了解三个标准流:
- 标准输入:默认是键盘,命令从这里读取数据。
- 标准输出:默认是终端屏幕,命令将正常结果输出到这里。
- 标准错误:默认也是终端屏幕,命令将错误信息输出到这里。
关键点: 管道 () 只连接标准输出 和标准输入,它不会传递标准错误。
这意味着,如果管道中的第一个命令出错,错误信息会直接打印到你的屏幕上,而不会传递给下一个命令。
常用管道命令示例
下面是一些非常经典且实用的管道命令组合。
示例 1:查看系统进程并过滤
ps 命令列出所有进程,信息很多,如果你想只查看与 sshd 相关的进程:
# ps aux 列出所有进程,grep "sshd" 过滤出包含 "sshd" 的行 ps aux | grep "sshd"
分解:
ps aux:产生所有进程的列表(标准输出)。- 捕获这个列表。
grep "sshd":从捕获的列表中读取数据,并只打印出包含 "sshd" 的行。
示例 2:统计文件中的行数、单词数和字符数
cat 命令用于显示文件内容,wc 命令用于统计,我们可以用管道来统计一个文件的行数。
# 显示 /etc/passwd 文件内容,并统计总行数 cat /etc/passwd | wc -l
分解:
cat /etc/passwd:读取/etc/passwd文件的内容,并将其输出到标准输出。- 捕获文件内容。
wc -l:从标准输入读取内容,并统计其中的行数。
更简洁的写法(因为 wc 本身可以直接处理文件,所以这个例子更多是为了演示管道):
# 直接统计文件行数,更高效 wc -l /etc/passwd
示例 3:查找文件并批量处理
查找所有 .log 文件,并删除它们(注意:这个操作很危险,请谨慎使用)。
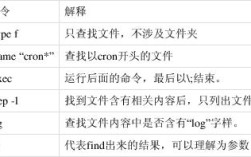
# find 查找文件,xargs 将文件列表作为参数传给 rm 命令 find /var/log -name "*.log" | xargs rm -f
分解:
find /var/log -name "*.log":在/var/log目录下查找所有以.log结尾的文件,并将它们的完整路径输出到标准输出。- 捕获文件路径列表。
xargs:这是一个强大的工具,它从标准输入中读取数据,并将其转换成命令行参数,然后执行后面的命令。rm -f会删除xargs传给它的所有文件。
示例 4:实时监控日志文件
tail -f 命令可以实时跟踪文件的增长,结合 grep,可以只过滤出你关心的日志。
# 实时查看 Nginx 的访问日志,只过滤出包含 "POST" 请求的行 tail -f /var/log/nginx/access.log | grep "POST"
分解:
tail -f /var/log/nginx/access.log:持续监控access.log文件末尾的新增内容,并实时输出。- 捕获这些新内容。
grep "POST":实时过滤出包含 "POST" 字符串的行。
示例 5:排序和去重
sort 对行进行排序,uniq 可以去除连续的重复行,一个常见的组合是先排序,再去重,因为 uniq 只能处理相邻的重复行。
# 对 /etc/passwd 文件的所有用户名进行排序,并去除重复项 cut -d: -f1 /etc/passwd | sort | uniq
分解:
cut -d: -f1 /etc/passwd:以冒号 为分隔符,提取/etc/passwd文件的第一列(用户名)。- 传递给
sort。 sort:对用户名进行排序。- 传递给
uniq。 uniq:去除排序后连续的重复用户名。
高级用法:|& 和 tee
|& (或 2>&1 |)
你不仅想把标准输出传递给下一个命令,也想把标准错误一起传递,这时就需要 |&。
# 同时将 command1 的标准输出和标准错误都传递给 command2 command1 |& command2
这等同于 command1 2>&1 | command2,意思是“先将标准错误重定向到标准输出,然后再通过管道传递”。
示例:
# 尝试读取一个不存在的文件,grep 会同时捕获 "No such file" 的错误信息 cat non_existent_file.txt |& grep "file"
tee 命令
tee 命令就像一个“T”形接头,它从标准输入读取数据,然后将其同时写入到指定的文件和标准输出。
这在你既想看到命令的输出,又想将其保存到文件时非常有用。
语法:
command | tee filename
示例:
# 将 who 命令的结果同时显示在屏幕上,并保存到 users.log 文件中 who | tee users.log
你也可以让 tee 追加内容而不是覆盖:
date | tee -a users.logtee 也可以和多个命令一起使用:
# 将 ls 的结果同时显示在屏幕、保存到 file_list.txt,并传递给 wc 统计行数 ls | tee file_list.txt | wc -l
注意事项
- 命令必须是外部命令:管道连接的是进程,像
if,for,while,echo(Shell 内置命令) 这样的命令不能直接作为管道的接收端,因为它们在 Shell 内部执行,不创建新的进程,通常需要使用bash -c或command来处理。 - 性能考虑:对于处理海量数据,管道非常高效,因为它是在内存中流式传输,避免了磁盘 I/O,但如果中间某个命令处理速度慢,会成为整个管道的瓶颈。
- 调试:调试管道命令时,如果某个环节出错,很难定位是哪个命令的问题,可以尝试分段执行,或者使用
tee将中间结果输出到文件进行检查。
管道是 Shell 脚本和命令行操作的灵魂,掌握它,你就能将一系列简单的命令组合成强大的工具,高效地完成各种复杂的数据处理任务,多加练习,你会发现它能让你的工作效率大大提升。