curl 是一个功能强大的命令行工具,用于传输数据,支持多种协议,包括 HTTP、HTTPS、FTP、FTPS 等,在下载大文件时,单线程下载往往速度较慢,而利用 curl 实现多线程下载可以显著提高下载效率,本文将详细介绍如何使用 curl 命令实现多线程下载,包括基本原理、常用参数、实际操作示例以及注意事项。

curl 多线程下载的原理是通过同时建立多个连接,分别下载文件的 different 部分,最后将这些部分合并成一个完整文件,这种方法可以有效利用网络带宽,减少下载时间,需要注意的是,并非所有服务器都支持多线程下载,如果服务器禁止了多连接请求,可能会导致下载失败或速度受限。
实现 curl 多线程下载通常需要结合其他工具,如 GNU Parallel 或自己编写脚本,以下是几种常用的方法:
使用 GNU Parallel 实现 curl 多线程下载
GNU Parallel 是一个强大的 shell 工具,可以并行执行命令,以下是一个使用 GNU Parallel 和 curl 实现多线程下载的示例:
安装 GNU Parallel(如果尚未安装):

- 在 Debian/Ubuntu 系统上:
sudo apt-get install parallel - 在 CentOS/RHEL 系统上:
sudo yum install parallel
假设我们要下载一个大文件,并使用 4 个线程:
seq 0 3 | parallel -j 4 curl -O -r {}/1000 http://example.com/largefile.zip
上述命令中,seq 0 3 生成数字 0 到 3,-j 4 表示使用 4 个线程,curl -O -r {}/1000 表示每个线程下载文件的 {}/1000 部分(第一个线程下载 0-999 字节,第二个线程下载 1000-1999 字节,以此类推),下载完成后,需要手动合并这些文件片段。
使用 curl 的 --range 参数结合脚本实现多线程下载
如果没有 GNU Parallel,可以编写一个简单的 shell 脚本实现多线程下载,以下是一个示例脚本:
#!/bin/bash
URL="http://example.com/largefile.zip"
THREADS=4
TEMP_DIR="./temp_download"
OUTPUT_FILE="largefile.zip"
# 创建临时目录
mkdir -p "$TEMP_DIR"
# 获取文件大小
FILE_SIZE=$(curl -s -I "$URL" | grep -i Content-Length | awk '{print $2}' | tr -d '\r')
# 计算每个线程下载的块大小
CHUNK_SIZE=$((FILE_SIZE / THREADS))
# 启动多线程下载
for i in $(seq 0 $((THREADS - 1))); do
START=$((i * CHUNK_SIZE))
END=$(((i + 1) * CHUNK_SIZE - 1))
if [ $i -eq $((THREADS - 1)) ]; then
END="" # 最后一个线程下载剩余部分
fi
(
curl -s -r "$START-$END" -o "$TEMP_DIR/part_$i" "$URL"
) &
done
# 等待所有线程完成
wait
# 合并文件
cat "$TEMP_DIR"/part_* > "$OUTPUT_FILE"
# 清理临时文件
rm -rf "$TEMP_DIR"
echo "Download completed: $OUTPUT_FILE"
使用 aria2c 工具(推荐)
虽然 aria2c 不是 curl,但它是一个更专业的多线程下载工具,支持 HTTP、HTTPS、FTP、BT 等协议,且比 curl 更容易实现多线程下载,以下是一个 aria2c 的示例:

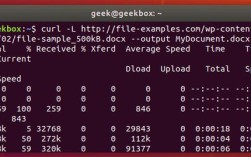
aria2c -x 4 -s 4 -c http://example.com/largefile.zip
参数说明:
-x 4:最大连接数(线程数)-s 4:同时下载数据块的数量-c:继续下载未完成的文件
curl 多线程下载的注意事项
- 服务器支持:确保目标服务器支持多线程下载(支持 Range 请求),可以通过
curl -I http://example.com/file检查响应头中是否包含Accept-Ranges: bytes。 - 线程数设置:线程数并非越多越好,过多的线程可能导致服务器拒绝连接或降低下载速度,建议根据网络环境和服务器性能设置合理的线程数(4-8 个线程)。
- 文件合并:手动合并文件片段时,需确保片段的顺序正确,可以使用
cat命令或sort命令按文件名排序后合并。 - 错误处理:添加错误检查机制,确保每个线程下载成功后再合并文件,可以使用
curl的-f参数(静默失败)或检查文件大小是否正确。
curl 多线程下载参数速查表
| 参数 | 说明 | 示例 |
|---|---|---|
-O |
将输出保存为文件,文件名从 URL 中提取 | curl -O http://example.com/file.zip |
-r |
指定下载范围(字节) | curl -r 0-999 -o part1 http://example.com/file.zip |
-s |
静默模式,不显示进度信息 | curl -s http://example.com/file.zip |
-L |
跟随重定向 | curl -L http://example.com/file.zip |
-C - |
断点续传 | curl -C - -O http://example.com/file.zip |
--range |
同 -r,指定下载范围 |
curl --range 0-999 -o part1 http://example.com/file.zip |
相关问答 FAQs
Q1:curl 多线程下载时,如何确保下载的文件片段顺序正确?
A1:在合并文件片段时,可以通过文件名中的序号(如 part_0, part_1)按数字顺序合并,使用 cat $(ls -v temp_dir/part_*) > output_file 命令,ls -v 会按数字顺序排序文件名,在生成文件片段时,确保每个线程的序号与片段顺序一致(如第一个线程下载 0-999 字节并保存为 part_0)。
Q2:如果服务器不支持多线程下载,curl 多线程下载会失败吗?
A2:是的,如果服务器不支持 Range 请求(即响应头中没有 Accept-Ranges: bytes),curl 的 -r 或 --range 参数将无法使用,多线程下载会失败,curl 会返回错误信息,如 HTTP/1.1 416 Range Not Satisfiable,建议使用 curl -I http://example.com/file 检查服务器是否支持多线程下载,或改用单线程下载(直接使用 curl -O)。