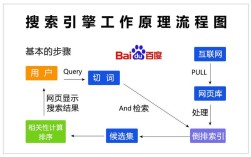
制作一个搜索引擎是一个涉及多个技术层面的复杂过程,需要从需求分析、技术选型、数据采集、索引构建到查询处理和结果展示等环节进行系统化设计,以下将详细拆解这一流程,帮助理解如何从零开始构建一个搜索系统。

明确搜索需求是基础,需要确定搜索的目标领域(如通用网页、电商商品、学术文献等)、数据规模(预计索引的文档数量)、查询类型(关键词搜索、模糊搜索、语义搜索等)以及性能要求(响应时间、并发量等),一个面向企业内部文档的搜索引擎与一个面向互联网的通用搜索引擎,在技术实现上会有显著差异,企业内部搜索可能更注重精准匹配和权限控制,而通用搜索则需要处理海量数据并优化相关性排序。
接下来是技术选型,这直接影响搜索系统的效率和可扩展性,对于中小型项目,基于开源工具的方案是常见选择,数据采集层,可以使用爬虫框架(如Scrapy、Apache Nutch)抓取网页或对接数据库获取结构化数据;对于实时性要求高的场景,可采用消息队列(如Kafka)接入实时数据流,数据处理与存储层,原始数据需经过清洗(去重、分词、去停用词等),非结构化数据(如文本)需通过分词器(如IKAnalyzer、Jieba)处理为词元,结构化数据可直接存储在关系型数据库(如MySQL)或NoSQL数据库(如MongoDB)中,索引构建层,核心是选择合适的搜索引擎库或服务,Elasticsearch是目前最流行的开源搜索引擎,基于Lucene构建,提供强大的全文检索、聚合分析和分布式扩展能力;对于需要更高性能的场景,可考虑Solr(同样基于Lucene)或商业搜索引擎如Algolia,应用层,需开发后端API(如使用Spring Boot、Django)处理查询请求,并设计前端界面(如React、Vue)展示结果。
数据采集与预处理是构建索引的前提,以网页搜索为例,爬虫需要遵守robots协议,避免对目标网站造成过大压力,并通过URL去重策略(如使用Bloom Filter)抓取唯一网页,抓取到的HTML文档需解析提取正文内容,过滤掉导航栏、广告等噪声,这一步可借助工具如BeautifulSoup或Jsoup,预处理还包括文本标准化(统一大小写、处理特殊字符)、分词(将句子切分为有意义的词语单元,中文分词需考虑歧义识别)以及词干提取或词形还原(如将"running"还原为"run"),对于多语言支持,需选择对应的分词器,例如Elasticsearch的"standard"分词器支持40多种语言。
索引构建是搜索系统的核心环节,直接影响查询效率,Elasticsearch的倒排索引结构是经典实现:每个词项对应一个倒排列表,记录包含该词的所有文档ID及词频、位置等信息,索引过程包括:1. 将文档分词后生成词项;2. 创建倒排索引,合并相同词项的倒排列表;3. 对索引进行优化(如段合并)以提高查询速度,索引的更新策略需权衡实时性和性能,批量索引(如每5分钟批量提交一次)比实时索引效率更高,但会增加数据延迟,对于分布式环境,Elasticsearch通过分片(Sharding)将索引拆分为多个部分存储在不同节点,并通过副本(Replication)保证高可用,分片数量需根据数据量和查询负载合理配置,通常建议每个分片大小在20GB-50GB之间。

查询处理与结果优化是用户体验的关键,当用户输入查询词时,系统需执行以下步骤:1. 查询解析(处理拼写错误、同义词扩展,如"电脑"自动匹配"计算机");2. 查询改写(根据用户历史行为或热门搜索调整查询);3. 倒排索引检索(快速定位包含查询词的文档);4. 相关性排序(如TF-IDF、BM25算法计算文档与查询的相关度,结合 PageRank、点击率等指标进行综合排序);5. 过滤与聚合(按时间、类别等条件过滤结果,或统计词频、计算平均值等),为提升性能,可采用缓存策略(如Redis缓存热门查询结果)、异步加载(先返回基础结果,再逐步加载补充内容)以及前端优化(如虚拟滚动减少DOM渲染压力)。
系统的监控与迭代,需通过日志收集(如ELK Stack)和性能监控工具(如Prometheus、Grafana)跟踪索引大小、查询延迟、错误率等指标,及时发现瓶颈,用户反馈(如点击行为、搜索无结果率)是优化排序算法和查询改写的重要依据,可通过A/B测试验证改进效果,若发现用户频繁修改查询词,可能说明分词效果不佳,需调整分词词典或引入语义理解模型。
相关问答FAQs
-
如何处理搜索中的同义词和拼写错误?
解决同义词问题可通过构建同义词词典(如"手机"="移动电话"="智能手机"),在索引时将同义词扩展为多个词项,或在查询时进行同义词替换,Elasticsearch的"synonym_tokenizer"支持自定义同义词规则,拼写错误可借助拼写检查算法(如基于编辑距离的Levenshtein距离,或基于统计的语言模型),在查询时返回"您是不是要找:XXX"的提示,或自动纠正查询词,Elasticsearch的"term suggester"可实现此功能,通过分析索引中的词项提供建议。 (图片来源网络,侵删)
(图片来源网络,侵删) -
如何提升搜索系统的实时性?
实时性优化需从数据采集和索引更新两方面入手,数据采集端可采用增量爬虫(只抓取更新过的页面)或实时数据接入(如通过Kafka流式处理),索引更新端,对于Elasticsearch,可使用"近实时"(Near Real-Time)搜索,通过刷新(Refresh)机制将内存中的索引缓冲区写入磁盘(默认1秒延迟),或使用"bulk API"批量提交数据减少IO开销,对于超低延迟场景(如毫秒级响应),可考虑内存数据库(如RedisSearch)或预计算热门查询结果,牺牲部分存储空间换取查询速度。