Linux下的df命令是disk free的缩写,主要用于显示Linux系统中文件系统的磁盘空间使用情况,通过df命令,用户可以快速查看各分区的总容量、已用空间、可用空间、使用率以及挂载点等信息,是系统管理和日常运维中不可或缺的工具,本文将详细介绍df命令的基本用法、常用选项、输出解读以及实际应用场景,帮助用户全面掌握这一实用工具。

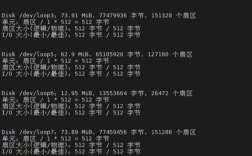
df命令的基本语法非常简单,直接在终端输入df即可查看当前系统中所有已挂载文件系统的磁盘使用情况,默认情况下,df命令会以512字节为单位显示磁盘空间,并且输出结果会按照文件系统的挂载点进行排序,在大多数Linux发行版中,执行df命令后可能会显示类似如下的内容:Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda1 20642492 15823456 3819036 81% / tmpfs 4096000 0 4096000 0% /dev/shm /dev/sdb1 524288000 123456789 400123456 24% /data,这里的Filesystem表示文件系统的设备名称或挂载点,1K-blocks表示以1KB为单位的总块数,Used表示已使用的空间,Available表示可用空间,Use%表示使用率,Mounted on表示挂载点。
为了获取更符合用户需求的信息,df命令提供了丰富的选项参数,其中最常用的选项包括-h、-T、-i和--total。-h选项以人类可读的格式显示磁盘空间,例如使用GB、MB、KB等单位代替原始的块数,这样更直观易读。-T选项用于显示文件系统的类型,如ext4、xfs、ntfs等,有助于用户区分不同类型的文件系统。-i选项则显示inode的使用情况,因为inode的数量直接关系到文件系统中可以创建的文件数量,在某些场景下比磁盘空间更重要。--total选项会在输出结果底部添加一行总计信息,方便用户快速了解整体磁盘使用情况,执行df -hT --total命令后,输出结果不仅包含各个分区的详细信息,还会在最后一行显示所有分区的总容量、已用空间、可用空间和使用率。
除了基本选项外,df命令还支持一些高级功能,如显示特定文件系统的信息,用户可以通过指定文件系统的设备名或挂载点来查看特定分区的使用情况,例如df /dev/sda1或df /home,df命令还可以通过--output选项自定义输出列,用户可以根据需要选择显示哪些信息,例如df --output=source,fstype,size,used,avail,pcent,target可以只显示源设备、文件系统类型、大小、已用空间、可用空间、使用率和挂载点这七列信息,这种自定义输出方式在编写脚本或生成报告时特别有用,可以避免无关信息的干扰。
在实际应用中,df命令的输出解读需要结合具体场景,当某个分区的使用率接近100%时,系统可能会出现性能下降或服务不可用的情况,此时需要及时清理磁盘空间或扩展分区,而inode使用率过高的问题则通常由大量小文件引起,需要通过查找并删除不必要的文件来解决,tmpfs文件系统是基于内存的虚拟文件系统,其大小通常与物理内存或交换分区相关,了解这一点有助于正确解读tmpfs的使用情况。

对于系统管理员而言,df命令还可以结合其他工具实现更强大的功能,通过df -h | grep -vE '^Filesystem|tmpfs'可以过滤掉文件系统标题和tmpfs行,专注于实际磁盘分区的使用情况,或者使用df -i | awk '{print $6}' | xargs -I {} sh -c 'echo "Mount point: {}"; find {} -xdev -type f | wc -l'来统计每个挂载点下的文件数量,从而辅助分析inode使用情况,这些组合使用的方式可以大大提高工作效率。
在脚本开发中,df命令的输出也可以被程序化处理,使用df -k --output=avail | tail -1可以获取系统的可用磁盘空间(以KB为单位),然后通过条件判断决定是否执行某些操作,或者利用df --output=pcent,target | grep -vE '^Use%' | sed 's/%//' | awk '$1 > 80 {print $2}'可以找出使用率超过80%的挂载点,这些技巧在自动化运维和监控系统中非常实用。
需要注意的是,df命令显示的是文件系统的使用情况,而不是磁盘分区的原始使用情况,因为文件系统可能会保留一定的空间(如保留块)给root用户使用,所以实际可用空间可能会比df显示的略少,某些文件系统(如LVM、RAID等)的显示方式可能与普通分区不同,需要用户具备一定的相关知识才能正确解读。
为了更直观地展示df命令的常用选项及其功能,以下表格总结了主要选项的含义和示例:

| 选项 | 全称 | 功能描述 | 示例 |
|---|---|---|---|
| -h | --human-readable | 以人类可读格式显示(GB、MB等) | df -h |
| -T | --print-type | 显示文件系统类型 | df -T |
| -i | --inodes | 显示inode信息 | df -i |
| --total | 显示总计行 | df --total | |
| --output=FIELDS | 自定义输出列 | df --output=size,used,avail | |
| -x | --exclude-type | 排除指定类型的文件系统 | df -x tmpfs |
| -t | --type | 只显示指定类型的文件系统 | df -t ext4 |
在实际使用中,用户可能会遇到一些常见问题,为什么df命令显示的磁盘空间与du命令不一致?这通常是因为df显示的是文件系统的整体使用情况,而du显示的是指定目录的实际占用空间,两者统计的范围和方式不同,另一个常见问题是某些目录(如/proc、/sys)没有占用磁盘空间,但df命令仍然会显示它们,这是因为这些是虚拟文件系统,不占用实际磁盘空间。
相关问答FAQs:
-
问:为什么df命令显示的磁盘空间与du命令统计的结果不一致? 答:df命令和du命令的统计方式和范围不同,df命令显示的是整个文件系统的使用情况,包括已分配但未使用的空间(如保留块),而du命令统计的是指定目录及其子目录中实际占用的空间,df的统计范围是整个文件系统,而du可以针对特定目录进行统计,因此两者结果存在差异是正常的。
-
问:如何使用df命令找出系统中使用率最高的分区? 答:可以通过管道和组合命令实现,例如执行df -h | grep -vE '^Filesystem|tmpfs|cdrom' | sort -k5 -n | tail -1可以过滤掉系统文件和虚拟文件系统,然后按使用率排序并显示使用率最高的分区,或者使用awk命令:df -h | awk 'NR>1 && $5!~/%$/ {print $5, $6}' | sort -k1 -n | tail -1,其中NR>1表示跳过标题行,$5!~/%$/表示过滤掉使用率中包含非数字字符的行(如tmpfs)。