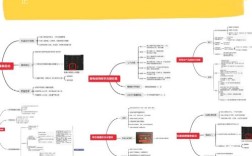
要做好运营维护工作,需要从目标规划、流程管理、技术支撑、团队协作和持续优化等多个维度系统推进,确保业务稳定运行并实现长期价值,明确运营维护的核心目标是保障系统可靠性、提升用户体验、控制成本并支持业务增长,因此所有工作都需围绕这些目标展开,在具体实践中,需建立清晰的职责分工和标准化流程,例如通过运维事件管理流程(监控-告警-定位-解决-复盘)确保问题快速响应,同时引入自动化工具减少人工操作失误,提升效率,技术层面,需构建完善的监控体系,覆盖基础设施(服务器、网络)、应用系统(性能、日志)和业务指标(用户活跃度、转化率),并制定差异化的SLA(服务等级协议),明确不同系统的可用性、故障恢复时间等要求,核心业务系统需达到99.99%的可用性,而次要系统可适当降低标准,以优化资源投入,数据备份与容灾方案必不可少,需定期进行恢复演练,确保在极端情况下业务能快速恢复,日常维护中,需定期进行系统巡检,包括硬件状态检查、安全漏洞扫描、性能瓶颈分析等,并建立知识库沉淀常见问题处理方案,缩短故障解决时间,团队协作方面,运维、开发、测试、业务等部门需建立常态化沟通机制,通过定期的跨部门会议共享系统状态和风险点,避免信息孤岛,引入DevOps理念推动运维与开发融合,例如通过CI/CD工具实现代码自动化部署,减少因手动操作引发的故障,成本控制也是运维维护的重要环节,需通过资源利用率分析、弹性扩缩容策略等优化云资源使用,避免资源浪费,采用混合云架构,将非核心业务部署在成本更低的公有云,而核心业务保留在本地数据中心,在用户体验优化上,需结合用户反馈和数据分析,持续改进系统性能,如通过CDN加速访问速度、优化数据库查询效率等,建立完善的考核与改进机制,通过MTTR(平均修复时间)、MTBF(平均无故障时间)等指标评估运维效果,并定期组织复盘会议,分析故障根因,推动流程和工具迭代,某电商平台通过引入AIOps(智能运维)平台,实现了故障预测和自动修复,将系统故障率降低了60%,同时运维人力成本减少30%,这一案例表明,技术赋能与流程优化相结合是提升运维效率的关键。

相关问答FAQs
Q1: 如何平衡运维效率与系统安全性?
A: 平衡运维效率与安全性需从技术和管理两方面入手,技术上,通过零信任架构实现最小权限访问控制,结合自动化工具(如Ansible、Terraform)标准化安全配置,减少人工操作漏洞;管理上,建立安全基线检查流程,定期进行渗透测试和合规审计,同时将安全指标纳入SLA,例如要求高危漏洞修复时间不超过24小时,低危漏洞不超过72小时,采用DevSecOps模式,在开发阶段嵌入安全扫描工具(如SonarQube),实现“安全左移”,从源头降低安全风险。
Q2: 运维团队如何应对突发流量高峰?
A: 应对突发流量高峰需提前制定预案并具备弹性扩容能力,通过历史流量数据和业务模型预测峰值资源需求,提前进行容量规划;利用云服务的弹性伸缩功能(如AWS Auto Scaling、阿里云ESS),根据CPU、内存等指标自动增减服务器实例,确保资源匹配业务需求;引入负载均衡(如Nginx、SLB)和缓存机制(如Redis、CDN),分散请求压力,减少后端系统负载,需建立流量限流和降级策略,例如在极端情况下优先保障核心功能(如下单、支付),暂时关闭非核心功能(如评论、推荐),避免系统崩溃,事后需分析流量峰值特征,优化架构和预案,提升未来应对能力。