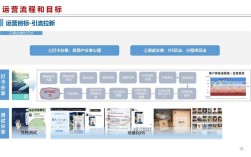
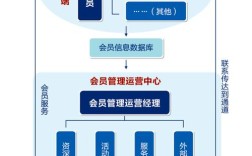
招聘系统后台作为企业人力资源管理的核心中枢,承担着从职位发布、简历筛选、面试安排到Offer发放的全流程数字化管理功能,其架构设计、功能模块与数据安全直接关系到招聘效率与人才质量,以下从系统架构、核心功能模块、技术实现要点、数据安全与隐私保护、未来发展趋势五个维度展开详细阐述。

系统架构设计
招聘系统后台通常采用微服务架构,通过模块化拆分实现高内聚低耦合,支持独立扩展与维护,整体架构可分为表现层、应用层、数据层与基础设施层四层:
- 表现层:面向管理员、HR、用人经理等不同角色,提供Web端管理后台及移动端适配界面,通过权限控制实现功能差异化展示。
- 应用层:核心业务逻辑层,包含招聘流程、用户管理、数据分析等微服务模块,通过RESTful API进行服务间通信,采用消息队列(如RabbitMQ、Kafka)处理异步任务(如简历解析、面试提醒)。
- 数据层:采用关系型数据库(如MySQL、PostgreSQL)存储结构化数据(如职位信息、候选人资料),非关系型数据库(如MongoDB、Elasticsearch)存储简历文档、日志等非结构化数据,结合数据仓库(如Hadoop、ClickHouse)支撑数据分析需求。
- 基础设施层:基于容器化技术(Docker、Kubernetes)实现弹性伸缩,通过CI/CD pipeline(如Jenkins、GitLab CI)自动化部署与迭代,确保系统高可用性(如多可用区容灾、负载均衡)。
核心功能模块
职位管理模块
- 职位发布与配置:支持多渠道(官网、招聘平台、社交媒体)职位同步发布,可自定义职位模板(包含JD自动生成、技能标签、汇报关系等字段),支持职位状态管理(草稿、发布、关闭、重启)。
- 职位权限控制:按部门/团队划分职位查看与编辑权限,用人经理可在线查看投递简历、面试反馈,但无权修改职位核心信息(如薪资范围、任职要求)。
简历管理模块
- 简历获取与解析:支持多渠道简历导入(手动上传、BOSS直聘、猎聘等API对接),通过NLP技术(如BERT模型)自动提取简历中的关键信息(姓名、联系方式、教育背景、工作经历、技能标签),结构化存储至数据库。
- 智能筛选与分类:基于规则引擎(如关键词匹配、学历/经验阈值)和机器学习模型(如协同过滤、决策树)实现简历初筛,自动标记“推荐”“待定”“不通过”状态,支持HR自定义筛选条件组合。
候选人管理模块
- 候选人全生命周期跟踪:建立候选人档案库,记录从投递、面试、背调到入职/淘汰的全流程状态,支持添加标签(如“被动候选人”“急招岗位”)、备注(如沟通记录、面试官反馈)。
- 人才库激活:对未通过当前岗位筛选的候选人,自动匹配未来相似职位并发送推荐信息,支持设置人才库保留期限(如1-3年),定期触发激活提醒。
面试管理模块
- 面试流程自动化:根据职位级别自动触发面试流程(初筛→业务面→终面),支持多轮面试安排(线上/线下),系统自动同步面试官日历(如对接Outlook、钉钉),发送面试邀请(邮件/短信/系统消息)。
- 面试评估与协作:提供标准化面试评估模板(如STAR法则提问库、打分维度),面试官可在线填写反馈并提交至系统,HR实时汇总评估结果,自动触发下一环节(如终面通过则进入Offer流程)。
Offer与入职管理模块
- Offer生成与发送:内置Offer模板库(支持多语言、多地区合规条款),自动关联候选人薪资、岗位、入职时间等信息,集成电子签名(如e签宝、法大大)实现Offer在线签署,签署状态实时同步。
- 入职准备与跟进:Offer签署后自动触发入职任务清单(如背景调查、工位安排、设备采购),发送入职须知给候选人,支持HR查看候选人材料提交进度(如学历认证、体检报告)。
数据分析与报表模块
- 多维度数据看板:实时展示招聘关键指标(KPI),如简历转化率(投递→面试→Offer)、招聘周期、渠道有效性(各平台简历量与质量比)、人均招聘成本(CPH)、Offer接受率等。
- 自定义报表与导出:支持按部门、岗位、时间段等维度生成报表(Excel、PDF格式),提供趋势分析(如季度招聘量变化)、对比分析(如不同渠道ROI),辅助招聘策略优化。
技术实现要点
性能优化
- 高并发处理:针对招聘高峰期(如春招、秋招),通过缓存(Redis)存储热点数据(如热门职位、简历模板),采用CDN加速静态资源访问,数据库读写分离(主库写入、从库查询)降低压力。
- 响应速度保障:对简历解析、智能筛选等耗时操作采用异步处理,通过任务队列(如Celery)分批执行,避免用户请求阻塞;前端采用懒加载、虚拟滚动等技术提升页面渲染效率。
集成能力
- 第三方系统集成:支持与OA系统(如钉钉、企业微信)单点登录及组织架构同步,与背景调查平台(如背调宝)、薪资核算系统(如SAP)API对接,实现数据流转自动化。
- 开放平台接口:提供标准化RESTful API,支持企业自建招聘小程序、APP或对接内部HRIS系统,确保数据互通与业务扩展。
智能化应用
- AI辅助决策:在简历筛选阶段引入NLP模型,分析候选人与职位的语义匹配度(如技能关键词权重、项目经验相关性);通过历史招聘数据训练预测模型,预估岗位招聘难度、候选人到岗概率。
- 聊天机器人:部署智能客服机器人(如基于Rasa框架),7×24小时解答候选人咨询(如职位详情、投递状态),自动过滤无效简历(如重复投递、信息不全),减轻HR工作负担。
数据安全与隐私保护
数据加密与存储
- 传输加密:采用HTTPS协议确保数据传输安全,敏感信息(如身份证号、银行账户)通过AES-256加密存储,数据库访问IP白名单限制,防止未授权访问。
- 数据脱敏:在非生产环境(如测试、开发)对候选人隐私信息(手机号、邮箱)进行脱敏处理(如138****1234),日志中避免记录敏感字段。
权限与审计
- 细粒度权限控制:基于RBAC(基于角色的访问控制)模型,设置权限层级(如超级管理员、HR专员、用人经理),最小权限原则(如HR仅可查看本部门候选人信息),操作日志记录(谁在何时做了何操作)。
- 合规性保障:遵守GDPR、《个人信息保护法》等法规,支持用户数据查询、删除、导出请求,简历数据保留期限到期后自动归档或删除,避免数据滥用风险。
未来发展趋势
- 全流程AI化:从简历筛选到面试评估,AI将深度参与决策(如AI面试官初步行为分析、候选人性格特质预测),但需平衡效率与公平性,避免算法偏见。
- 体验升级:候选人端将更加注重交互友好性(如AR面试模拟、职位个性化推荐),HR端通过低代码平台支持自定义流程配置,无需开发即可调整招聘规则。
- 生态化整合:招聘系统将与人才发展、绩效管理模块深度集成,形成“选-育-用-留”全周期人才管理闭环,结合组织能力分析提供战略决策支持。
相关问答FAQs
Q1: 招聘系统后台如何确保不同角色(如HR、用人经理、候选人)的数据权限隔离?
A1: 系统采用基于角色的访问控制(RBAC)模型,通过角色-权限矩阵实现数据隔离,具体包括:① 角色定义:创建超级管理员、HR专员、用人经理、候选人等角色;② 权限配置:为角色分配最小必要权限(如HR可管理所有职位,用人经理仅可查看本部门职位及投递简历);③ 数据过滤:在SQL查询中通过部门ID、职位ID等字段动态过滤数据,确保角色仅能访问授权范围内的信息;④ 操作日志审计:记录所有数据访问与修改操作,异常行为实时告警(如非部门经理查看其他部门候选人简历)。
Q2: 招聘系统后台如何应对大规模简历投递高峰期的性能挑战?
A2: 针对高峰期性能挑战,系统采取“缓存+异步+扩展”组合策略:① 缓存优化:使用Redis缓存热门职位信息、简历模板等静态数据,减少数据库访问压力;② 异步处理:对简历解析、智能筛选等耗时操作通过消息队列(如Kafka)异步执行,避免阻塞用户请求;③ 数据库优化:采用读写分离架构,主库负责写入,从库承担查询任务,对大表(如简历表)进行分库分表(按时间或部门);④ 弹性扩展:基于Kubernetes实现容器自动伸缩,根据CPU/内存使用率动态增减应用实例,同时通过CDN加速静态资源访问,确保系统在高并发下响应时间控制在3秒以内。