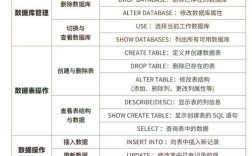
HBase作为Apache Hadoop生态系统中的分布式、面向列的NoSQL数据库,提供了丰富的命令行工具(Shell)用于管理表、数据以及集群操作,以下将详细介绍HBase Shell的核心命令,涵盖表管理、数据操作、集群维护等多个方面,并通过表格形式对比常用命令的语法与功能。

表管理命令
表是HBase数据存储的基本单位,创建、修改和删除表是日常操作的基础,创建表时需指定表名和列族信息,例如create 'table_name', 'cf1', 'cf2',其中cf1和cf2为列族名称,列族一旦创建不可直接修改,但可以通过disable和alter命令进行间接调整,如先禁用表disable 'table_name',再执行alter 'table_name', NAME => 'cf1', VERSIONS => 3修改列族属性,查看表结构使用describe 'table_name',命令会返回列族、版本数、TTL等详细信息,删除表前必须先禁用表,即disable 'table_name'后执行drop 'table_name',否则会报错。list命令用于列出所有表,exists 'table_name'检查表是否存在,is_enabled 'table_name'和is_disabled 'table_name'则分别判断表状态。
数据操作命令
数据操作包括插入、查询、修改和删除,是HBase最核心的功能,插入数据使用put命令,语法为put 'table_name', 'row_key', 'cf:column', 'value', [timestamp],其中row_key是行键,cf:column为列标识(列族:列名),timestamp为可选的时间戳,例如put 'user', '1001', 'info:name', 'Alice'表示向user表的1001行插入info列族下的name列,值为Alice,查询数据有多种方式:get 'table_name', 'row_key'获取整行数据,get 'table_name', 'row_key', 'cf:column'获取特定列值;scan 'table_name'扫描全表,可通过STARTROW => 'start_key'和STOPROW => 'stop_key'限制扫描范围,或FILTER => "ValueFilter(=, 'binary:value')"添加过滤条件,批量插入数据时,可使用put命令循环执行,或通过MapReduce批量导入,修改数据本质上是覆盖操作,即通过新的put命令更新列值,HBase会根据时间戳保留最新版本,删除数据分为两类:delete 'table_name', 'row_key', 'cf:column'删除指定列的某一版本数据,deleteall 'table_name', 'row_key'删除整行数据,若需清空表,可使用truncate 'table_name',该命令会先禁用表、删除所有数据,再重新创建表结构。
集群与维护命令
HBase集群维护命令用于监控集群状态、管理表分区和备份。status命令查看集群状态,如status 'simple'返回简要信息,status 'summary'显示详细负载情况。regioninfo命令可查看Region位置信息,move 'region_name', 'server_name'手动迁移Region以实现负载均衡。compact命令用于合并StoreFile,减少小文件数量,major_compact 'table_name'执行 major compact,会合并所有文件并删除过期数据,但会消耗大量资源。flush命令将内存中的数据写入HDFS,形成新的StoreFile。assign 'region_name'和unassign 'region_name'分别用于分配和取消分配Region,备份与恢复方面,export 'table_name', 'hdfs_path'可将表数据导出到HDFS,import 'table_name', 'hdfs_path'则从HDFS导入数据。balance_switch true/false开启或关闭集群自动负载均衡,split 'table_name'手动触发表分区。
常用命令对比表
| 命令类型 | 命令语法 | 功能说明 |
|---|---|---|
| 表管理 | create 'table', 'cf' | 创建表,指定列族 |
| disable 'table' | 禁用表 | |
| drop 'table' | 删除表(需先禁用) | |
| describe 'table' | 查看表结构 | |
| 数据操作 | put 'table', 'row', 'cf:col', 'val' | 插入或更新数据 |
| get 'table', 'row' | 获取单行数据 | |
| scan 'table', {FILTER => '...'} | 扫描表并支持过滤 | |
| delete 'table', 'row', 'cf:col' | 删除指定列数据 | |
| 集群维护 | status | 查看集群状态 |
| compact 'table' | 合并StoreFile | |
| flush | 刷新内存数据到HDFS | |
| balance_switch true/false | 开启/关闭自动负载均衡 |
相关问答FAQs
Q1: HBase中如何批量删除数据?
A1: HBase没有直接的批量删除命令,但可通过以下方式实现:1)使用deleteall命令结合循环脚本(如Python或Shell)逐行删除;2)通过MapReduce任务批量删除,需编写自定义Mapper读取待删除行键,调用HBase API执行删除;3)对于范围删除,可先disable表,然后删除HDFS上的对应HFile文件,再enable表(需谨慎操作,可能导致数据不一致)。

Q2: 为什么HBase的get命令查询不到刚插入的数据?
A2: 可能原因包括:1)数据还在MemStore中未Flush到HDFS,可通过flush命令手动刷新;2)查询的行键或列名错误,需确认put命令中的row_key和cf:column是否与查询条件一致;3)数据被其他客户端覆盖或删除,可通过scan命令扫描全表验证;4)Region可能处于迁移或分裂状态,导致暂时不可用,可通过regioninfo命令检查Region状态。