智联招聘作为中国领先的在线招聘平台,其技术架构和开发工具的选择直接关系到平台的性能、稳定性及用户体验,从整体来看,智联招聘的开发涉及多端、多语言、多框架的组合,采用分布式微服务架构,结合云计算、大数据等技术,以支撑海量用户访问和数据处理需求,以下从技术栈、开发框架、数据库、中间件、云服务等多个维度详细解析智联招聘的开发技术细节。

在开发语言选择上,智联招聘的后端开发主要采用Java语言,这得益于Java在大型企业级应用中的稳定性、跨平台性及丰富的生态系统,Java被广泛用于核心业务逻辑处理,如用户管理、职位发布、简历解析、匹配算法等模块,针对部分高性能场景,如实时推荐系统、高并发接口等,也会引入Go语言,利用其轻量级协程和高效并发处理能力提升系统性能,前端开发则以JavaScript为核心,配合TypeScript增强代码可维护性,通过React、Vue等现代前端框架构建用户交互界面,确保页面的响应速度和动态渲染能力,移动端开发则采用原生开发与跨平台开发结合的方式,iOS端使用Swift/Objective-C,Android端使用Kotlin/Java,同时针对部分功能模块引入React Native或Flutter实现跨平台复用,提升开发效率。
在开发框架层面,后端主要基于Spring Cloud Alibaba生态构建微服务架构,通过Spring Boot实现快速开发和服务治理,结合Nacos作为服务注册与配置中心,Sentinel实现流量控制和服务熔断,Dubbo作为RPC框架服务间通信,这些框架的协同使用,有效实现了服务的解耦、弹性扩展和高效运维,前端开发则采用Webpack作为模块打包工具,配合Babel进行代码转译,使用Redux或Vuex进行状态管理,通过Ant Design、Element UI等组件库快速构建标准化UI界面,移动端开发中,原生应用会使用iOS的UIKit框架和Android的Jetpack组件库,而跨平台应用则通过React Native的Native模块或Flutter的Platform Channel实现与系统原生能力的交互。
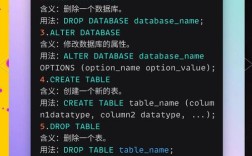
数据库技术选型上,智联招聘根据业务场景特点采用多种数据库混合部署的方式,核心业务数据如用户信息、职位数据等存储在MySQL关系型数据库中,利用其事务特性和SQL查询能力保证数据一致性;对于海量简历数据、日志数据等非结构化或半结构化数据,则采用Elasticsearch实现全文检索和数据分析,通过Hadoop HDFS存储原始数据,并结合Hive或Spark SQL进行离线数据处理;缓存层使用Redis,存储热点数据如用户会话、职位推荐结果等,降低数据库访问压力,提升响应速度,针对分布式事务场景,还引入Seata等中间件保证跨服务数据的一致性。
中间件和基础设施方面,消息队列采用RocketMQ或Kafka,用于处理异步任务,如简历解析通知、职位推荐推送等,实现系统解耦和流量削峰;分布式存储使用MinIO或阿里云OSS存储用户上传的简历、头像等文件;容器化部署基于Docker和Kubernetes(K8s),结合Jenkins实现CI/CD自动化部署,通过Prometheus和Grafana进行系统监控和告警,确保服务的稳定运行,在云服务选型上,智联招聘主要采用阿里云、腾讯云等公有云服务,利用其弹性计算、负载均衡、CDN等能力,根据业务流量动态调整资源,控制成本。

大数据和AI技术是智联招聘的核心竞争力之一,在数据处理方面,通过Flink进行实时流处理,分析用户行为数据,实现职位实时推荐;使用Spark MLlib或TensorFlow构建机器学习模型,优化简历与职位的匹配算法,提升推荐精准度;NLP技术被广泛应用于简历解析、职位描述结构化、智能问答等场景,通过自然语言处理技术将非结构化文本转化为结构化数据,支撑智能匹配功能,还通过数据中台建设,整合多源数据,为业务决策提供数据支持。
在安全防护方面,智联招聘采用多层次安全策略,包括WAF(Web应用防火墙)防御SQL注入、XSS等攻击,SSL/TLS加密传输数据,JWT实现无状态认证,结合风控系统识别异常登录和恶意操作,保障用户数据和平台安全,性能优化方面,通过多级缓存、数据库读写分离、分库分表、CDN加速等技术手段,解决高并发场景下的性能瓶颈,确保平台在“双十一”等招聘高峰期的稳定运行。
相关问答FAQs:
-
智联招聘的移动端开发为什么采用原生+跨平台结合的方式?
答:原生开发(如iOS的Swift、Android的Kotlin)能够充分利用系统原生API和硬件能力,提供更流畅的用户体验和更强的性能,适合处理核心功能模块;而跨平台开发(如React Native、Flutter)通过一套代码多端运行,显著降低开发成本和维护难度,适合功能相对稳定、复用性高的模块,两者结合既能保证用户体验,又能提升开发效率,适应快速迭代的需求。 (图片来源网络,侵删)
(图片来源网络,侵删) -
智联招聘如何处理海量简历数据的存储和检索?
答:针对海量简历数据,智联招聘采用“分布式存储+搜索引擎”的方案,非结构化的简历原文存储在HDFS或对象存储(如阿里云OSS)中,通过Elasticsearch建立简历内容的倒排索引,实现关键词的快速检索;同时利用Spark进行离线数据处理,提取简历中的结构化信息(如工作经历、技能标签)存储到MySQL中,支持复杂条件查询;通过Redis缓存高频访问的简历数据,降低数据库负载,确保检索响应速度。